Scala, Processing and Spark
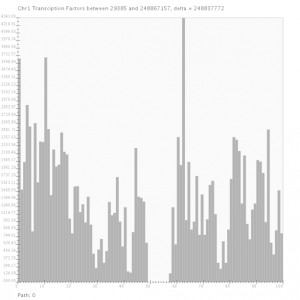
As discussed earlier, we use Spark as a backend for handling the data to be analysed. Since our group is working on Visual Analytics, obviously, something visual or graphical should come out.
Because the group had already be using Processing, I looked into using it as a frontend as well. In this post, I describe how to get Processing and Spark to work together.
Please note that I’m developing in Scala. This is a nice example of using Java libraries (Processing) in Scala.
Interface Scala (Spark) and Processing
In order to make life easy, I included all Processing libraries into my build. This is done, e.g., by creating a directory libs under the project dir that contains all the jar files from the Processing distribution and called it libs.
Sbt config
The following is the current build.sbt file:
name := “BioTrees”
version := “1.0.0”
scalaVersion := “2.9.3”
//scalacOptions ++= Seq(“-deprecation”, “-feature”)
libraryDependencies += “org.scalatest” %% “scalatest” % “1.9.1” % “test”
libraryDependencies += “junit” % “junit” % “4.10” % “test”
libraryDependencies += “org.apache.spark” %% “spark-core” % “0.8.0-incubating”
unmanagedBase <<= baseDirectory { base => base / “libs” }The last line is for adding the libs directory with the Processing jars to the classpath.
Code
It is sufficient to add 2 things to the code:
First the includes:
import processing.core._
import PConstants._
import PApplet._And then, a Main class has to be defined which contains the code for drawing the canvas.
class Main extends PApplet {
override def setup {
...
}
override def draw {
...
}
}Serialization
When passing global variables to Spark, we run into serialization issues:
13/12/13 10:56:59 INFO scheduler.DAGScheduler: Failed to run reduce at biotree.scala:109 [error] (Animation Thread) org.apache.spark.SparkException: Job failed: java.io.NotSerializableException: processing.core.PApplet$InternalEventQueue org.apache.spark.SparkException: Job failed: java.io.NotSerializableException: processing.core.PApplet$InternalEventQueue . . .
In my case, the cause is that I mixed Spark class references with PApplet (from Processing). The latter can not be serialized and thus gives problems. </span>The fix is to (simply stated) keep Spark code apart from Processing code. I added an object containing Spark code to encapsulate the relevant parameters.
Processing in Scala
There are no big differences when using Processing libraries from Scala. Below is a little snippet of code that shows what it looks like:
override def setup() = {
size(w, h);
background(255)
stroke(200)
fill(180)
rectMode(CORNERS)
textSize(10)
}
override def keyPressed() = {
// setup
if (key == CODED) {
if (keyCode == UP) input = "u"
else if (keyCode == DOWN) input = "d"
else if (keyCode == LEFT) input = "l"
else if (keyCode == RIGHT) input = "r"
}
clearScreen()
redraw()
}Current Status
The screenshot above shows the current status of our Proof-Of-Concept, combining Processing for visualisation and Spark for parallel interactive querying of the data. In fact, we also developed an intermediate layer (a tree structure), but this will be covered in a future post.