Hadoop tutorial
Contents
This blog post accompanies my course on managing large datasets at the KU Leuven. The aim of the exercise is to get acquainted with mapreduce in practice. Meanwhile, we’ll also touch on Docker.
There are many ways to get the answer to the exercises below, just even using regular commands like cut, sort, awk, etc. Obviously, we want you to do these using Hadoop…
Preparation
As it will be overkill to install Hadoop on your computer just to do these exercises, we’ll use Docker containers. Docker (see http://docker.io) is a system that allows for bundling up software that runs as a service (e.g. a web browser, or a database server) and deploy these very easily.
For information on what Docker is, and how to use it, see e.g. the following: http://prakhar.me/docker-curriculum/ (until and including section 2.4 - Dockerfile)
Installing Docker
Installation instruction can be found here:
- Windows: https://docs.docker.com/windows/step_one/
- Mac: https://docs.docker.com/mac/step_one/
- Linux: https://docs.docker.com/linux/step_one/
In each of these, the last step of the instructions includes a “hello world” to check if everything works as it should.
Download the docker images for hadoop
This is strictly not necessary, because a docker run will do this automatically if the image is not available locally. We do this however to not have to wait the moment that we do the exercise.
docker pull sequenceiq/hadoop-docker:2.7.0
See sequenceiq’s github page for more information on this specific image.
Download the data for the exercises
Make a new directory on your machine, and download the data in there.
wget http://vda-lab.github.io/assets/beer-exercise.tar.gz tar -xvzf beer-exercise.tar.gz cd beer
This will create a new directory called “beer”, containing both the data file beers.csv, and the scripts that need to be edited (mapper1.rb, reducer1.rb, …).
Exercises
The beer dataset looks like this:
,make,type,alcoholpercentage,brewery 1,3 Schténg,hoge gisting,6,Brasserie Grain d'Orge 2,400,blond,5.6,'t Hofbrouwerijke voor Brouwerij Montaigu 3,IV Saison,saison,6.5,Brasserie de Jandrain-Jandrenouille 4,V Cense,hoge gisting;special belge,7.5,Brasserie de Jandrain-Jandrenouille 5,VI Wheat,hoge gisting;tarwebier,6,Brasserie de Jandrain-Jandrenouille 6,Aardmonnik,oud bruin,8,De Struise Brouwers 7,Aarschotse Bruine,bruin,6,Stadsbrouwerij Aarschot 8,Abbay d'Aulne Blonde des Pères 6,abdijbier;blond,6,Brasserie Val de Sambre 9,Abbay d'Aulne Brune des Pères 6,abdijbier;bruin,6,Brasserie Val de Sambre ...
We want to find out the following things:
- Exercise 1 - How many beers are there for each alcoholpercentage?
- Exercise 2 - Which are the actual beers with that average percentage?
- Exercise 3 - For each alcohol percentage: how many beers and how many breweries?
Exercise 1
Mapper and reducer on the linux command line
In a mapreduce setting, a “mapper” applies a certain function to every input, which is then handed to a “reducer” which combines these. The exchange format between the two are key-value pairs.
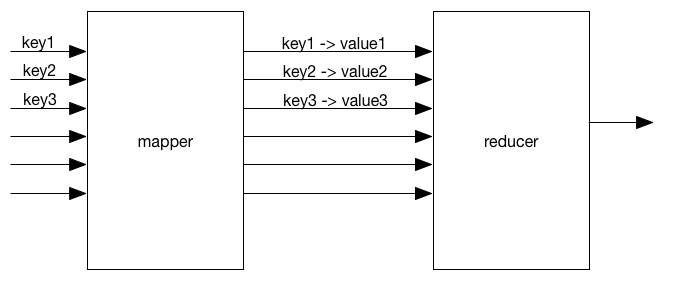
The value associated with each key can be a scalar (number or string), but also an array or dictionary (in python lingo; “object” in javascript-speak).
Wordcount example
A typical mapper.py script for a wordcount will look like this:
import sys
for line in sys.stdin:
line = line.strip()
words = line.split(' ')
for word in words:
print word, "\t1"This code takes each line of the input, splits it into words (split(' ')), and prints out each word followed by a tab and a 1. So the output will be:
lorem 1 ipsum 1 dolor 1 sit 1 amet 1 consectetur 1 ...
The accompanying reducer.py will look like this:
import sys
previous_key = ''
sum = 0
for line in sys.stdin:
line = line.strip()
key, count = line.split("\t")
count = int(count)
if key != previous_key:
if previous_key != '':
print previous_key, "\t", sum
sum = 1
previous_key = key
else:
sum += 1
print previous_key, "\t", sumTaking the sorted output from the mapper as input, the reducer will return actual number of times a word appeared in the document:
a 12 adipiscing 2 aliquam 1 aliquet 1 amet 3 ante 5 aptent 1 ...
Back to the beer
In this exercise, we will write (adapt) a mapper and reducer script to count the number of times a certain alcoholpercentage appears in the input file.
Take the scripts mapper1.py and reducer1.py, and edit the indicated lines.
## mapper1.py
import sys
for line in sys.stdin:
line = line.strip()
fields = line.split(',')
# Print the third field and a 1, separated by a tab.
ALTER_THIS_LINE## reducer1.py
import sys
previous_value = ''
sum = 0
for line in sys.stdin:
line = line.strip()
value, count = line.split("\t")
count = int(count) # The count is read as a string, but needs to be converted into an integer.
if value != previous_value:
# What needs to be done if a new value is encountered?
WRITE_CODE_HERE
else:
sum += 1Output from cat beers.csv | ./mapper1.py should look like this:
6 1 5.6 1 6.5 1 7.5 1 6 1 8 1 6 1 6 1 6 1 ...
Output from running cat beers.csv | ./mapper1.py | sort | ./reducer1.py should look like this:
0 1 0.25 2 0.3 1 0.4 1 0.5 3 1 1 1.2 2 1.3 1 1.4 2 1.5 8 ...
Running the mapper and reducer piped together (but including the sort!) is an easy way to check if your scripts do what they need to do, before you want to run these on a Hadoop cluster (see below).
Mapper and reducer using Hadoop
Instead of running a complete cluster of machines, we will run Hadoop in “single-node” mode. This means that we can use and test any functionality we need, but it will be slow. After all, instead of just running the pipe as before, we will have the overhead of the Hadoop system without being able to split the work across machines.
Running the hadoop container
We first need to get hadoop up and running on your machines. As we already pulled down the images, a docker run should be quick:
docker run -v $(pwd):/home/hadoop-exercise -it --rm sequenceiq/hadoop-docker:2.7.0 /etc/bootstrap.sh -bash
This will take a minute to start all services. You’ll end up with a command prompt that looks like this: bash-4.1# .
The hadoop command contains several subcommands, such as hadoop fs and hadoop jar (which we’ll touch upon).
Preparing the hadoop run
To run anything using Hadoop, we need to put all necessary files on the Hadoop Distributed File System (HDFS).
export PATH=$PATH:/usr/local/hadoop/bin cd /home/hadoop-exercise
hadoop fs -put mapper1.py hadoop fs -put reducer1.py hadoop fs -put beers.csv
If we were working on a large Hadoop cluster, this would split each file into chunks and distribute them among the different machines. In our case, it will all remain on our current machine, but moved into the Hadoop system. Use hadoop fs -ls to check if the files are copied to HDFS.
Running the hadoop mapreduce job
In order to run this map-reduce pipeline using hadoop, we will run the hadoop command with the jar subcommand. The “jar”-name refers to the file extension used for a java program. The java program we will run is one that takes a mapper and reducer, and sends a data file through them (= hadoop streaming). Other arguments necessary are: which file contains the mapper code, which file contains the reducer code, where should the output be stored, and which files need to be imported.
hadoop jar \ /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.0.jar \ -mapper "python mapper1.py" \ -reducer "python reducer1.py" \ -input beers.csv \ -output OutputDir \ -file mapper1.py \ -file reducer1.py \ -file beers.csv
Starting this command will send a lot of information to the screen:
16/03/29 03:54:27 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 16/03/29 03:54:29 INFO input.FileInputFormat: Total input paths to process : 31 16/03/29 03:54:30 INFO mapreduce.JobSubmitter: number of splits:31 16/03/29 03:54:30 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1459237999031_0001 16/03/29 03:54:31 INFO impl.YarnClientImpl: Submitted application application_1459237999031_0001 16/03/29 03:54:31 INFO mapreduce.Job: The url to track the job: http://455083e722e3:8088/proxy/application_1459237999031_0001/ 16/03/29 03:54:31 INFO mapreduce.Job: Running job: job_1459237999031_0001 16/03/29 03:54:42 INFO mapreduce.Job: Job job_1459237999031_0001 running in uber mode : false 16/03/29 03:54:42 INFO mapreduce.Job: map 0% reduce 0% 16/03/29 03:55:20 INFO mapreduce.Job: map 19% reduce 0% ...
If everything works as it should, you should see a “Job completed successfully” somewhere.
We can now check if the output was generated: there should be a new folder on HDFS called OutputDir. It should show up with hadoop fs -ls. To list the files in that folder itself, run hadoop fs -ls OutputDir.
You’ll see a file named part-00000. This is the actual output from your mapreduce job. In this particular example, there is only one output file. You can inspect the contents of that file while it’s still on HDFS using e.g. cat: hadoop fs -cat OutputDir/part-00000 | head . To actually copy the file to your local filesystem, run hadoop fs -getmerge OutputDir/ my-local-file.txt.
Question
Which alcoholpercentage is the most common?
Exercise 2
Above, we only got the average alcohol percentage as a number. But what if we want to have the actual names of those beers? We cannot just let the mapper return 1 as the value, but we need the actual beer name. So we want to see output like this, where the first column is the alcohol percentage, the second column is the number of beers with that percentage, and the third is a list of the actual beer names.
0 1 ['Gordon Finest Zero'] 0.25 2 ['Palm Green', 'Palm N.A'] 0.3 1 ['Edel-Brau'] 0.4 1 ['Star Blond'] 0.5 3 ['Alfri', 'Fancy', 'Jupiler NA'] 1 1 ['Belle-Vue LA'] 1.2 2 ['Blonde', 'Maltosa'] 1.3 1 ['Itters Bruin'] 1.4 2 ['Louwaege Dubbel Blond', 'Louwaege Faro'] ...
Basically, not much will have to happen in the mapper: it will just have to return the beer name instead of a 1 as the value. The reducer will be a bit more complex, though.
Your task
Adapt mapper2.py and reducer2.py to get the output as described above. Which 4 beers have an alcohol percentage of 4.2?
Exercise 3
For the next exercise, we want to find out not only how many beers are available for each alcohol percentage, but also the corresponding breweries. However, we do not want to have duplicates: some breweries will have several beers with the same alcoholpercentage. We only want to report these breweries once.
In contrast to the previous exercise, we now need to capture multiple things in the value: both the beer name and the brewery name. This can easily be achieved by joining them with a delimiter.
6 3 Schténg,Brasserie Grain d'Orge 5.6 400,'t Hofbrouwerijke voor Brouwerij Montaigu 6.5 IV Saison,Brasserie de Jandrain-Jandrenouille 7.5 V Cense,Brasserie de Jandrain-Jandrenouille 6 VI Wheat,Brasserie de Jandrain-Jandrenouille 8 Aardmonnik,De Struise Brouwers 6 Aarschotse Bruine,Stadsbrouwerij Aarschot 6 Abbay d'Aulne Blonde des Pères 6,Brasserie Val de Sambre ...
In the reducer script, you can then easily split these again:
for line in sys.stdin:
line = line.strip()
key, value = line.split("\t")
beer, brewery = value.split(',')
...Your task
Alter scripts mapper3.py and reducer3.py to create output that resembles this:
0 1 ['Gordon Finest Zero'] 1 ['Group John Martin'] 0.25 2 ['Palm Green', 'Palm N.A'] 1 ['Brouwerij Palm'] 0.3 1 ['Edel-Brau'] 1 ['Brouwerij Strubbe'] 0.4 1 ['Star Blond'] 1 ['Brouwerij Haacht'] 0.5 3 ['Jupiler NA', 'Alfri', 'Fancy'] 3 ['Brouwerij Roman', 'Brouwerij Bavik', 'Brouwerij Piedboeuf (InBev)'] ...
Columns are: alcohol percentage, number of beers, the list of beers, number of breweries, list of breweries.
Question
Which beers have a alcohol percentage of 1.2 percent? Which brewery or breweries make these beers?