Extended introduction to relational databases
This post is part of an extended version of the introduction to relational databases post, to be served as course material for the Software and Data Management course at UHasselt. The contents of this post is licensed as CC-BY: feel free to copy/remix/tweak/… it, but please credit your source.
- Part 1 (this post): Relational database design and SQL
- Part 2: Beyond SQL
- Part 3: Lambda architecture

For a particular year’s practicalities, see http://vda-lab.be/teaching
(Part of the content of this lecture is taken from the database lectures from the yearly Programming for Biology course at CSHL, and the EasySoft tutorial at http://bit.ly/x2yNDb, as well as from course slides created by Leandro Garcia Barrado)
Data management is critical in any science, including biology. In this course, we will focus on relational (SQL) databases (RDBMS) as these are the most common. If time permits we might venture into the world of NoSQL databases (e.g. MongoDB, ArangoDB, neo4j) to allow storing of huge datasets.
For relational databases, I will discuss the basic concepts (tables, tuples, columns, queries) and explain the different normalisations for data. There will also be an introduction on writing SQL queries. Document-oriented and other NoSQL databases (such as MongoDB) can often also be accessed through either an interactive shell and/or APIs (application programming interfaces) in languages such as perl, ruby, java, clojure, …
So what will we cover here?
Table of contents
- Table of contents
- 1. What is “data management”?
- 2. Data collection
- 3. Relational databases
- 4. Developing the database schema
- 5. SQL - Structured Query Language
- 6. Drawbacks of relational databases
1. What is “data management”?
Data management encompasses 3 parts:
- What data do we need and how are we going to collect it? In a clinical trial, for example, data to be collected is described in the protocol and entered into the Case Report Form (CRF); in an epidemiological study, data can however come from very different sources. In a DNA sequencing setting, the DNA sequences generates the raw data in a standardised format.
- How to store it on a computer in an efficient way? This is about database design and database normalisation. That is described further in this post.
- How to retrieve information from DBMS in a reliable way? We access the data using the Structured Query Language (SQL), which is the topic of the next post.
2. Data collection
Let’s look at some example life science fields where we collect data to make the rest of the session a bit more concrete.
2a. Clinical Trial
A clinical trial is a study involving the assessment of one or more regimens used in treating or preventing a specific illness or disease (McFadden, 2007). The design, aim, number of patients etc. depend on the phase of the clinical trial. Different types of data are collected:
- Administrative data describes information to uniquely identify a patient and their contact details. Often, the name cannot be used due to the fact that multiple people can have the same name, but more importantly to ensure minimal identifiability (privacy); therefore a unique patient ID is generated at enrolment. In addition, information like the name of the trial and name of the center in large multicenter trials are recorded.
- Research data is all information needed to answer study objective(s) in the protocol, including measurements of endpoints, relevant dates (study entry, treatment administration), etc. The amount of research data to be collected varies widely. It is important to collect only relevant data, as not all clinically relevant data is relevant research data. For example, exact timing of intervention may be relevant for clinical care (record in medical file), but not to answer research questions. Collection of irrelevant data increases time and effort to collect, enter, and process this data, increases the complexity of the database and risk for missing data, etc.
The trial protocol describes which data items need to be collected, based on which a Case Report Form (CRF) is developed. The CRF is the official clinical data-recording document used in a clinical study which stores all relevant patient info that is obtained in a clinical trial. It should be of high quality as a poor design can lead to unreliable data and possibly wrong conclusions of the study.
Items on a CRF are organised according to the following rationale:
- They should follow the time flow of the trial (when are the data collected?). For example, items collected at study entry (e.g., medical history, treatment allocation, etc.) are grouped together and as well as for all follow-up phases (e.g., primary endpoint measures, adverse effects at particular time point).
- The should reflect the logistics and practical organisation of the trial (where and by whom are the data collected?). For example: some data at study entry may be collected by the CRA, other data by the physician; some data at study entry may be gathered in the cardiology department, other data in the radiology department.
Separate sections/pages on the CRF are created for each logical division.
Below are two annotated pages from a CRF. The red annotations are meant for the data management department and indicate which variable in the database each piece of information is stored in.


2b. Epidemiological studies
Epidemiology is described as “the study of the occurrence and distribution of health-related states or events in specified populations, including the study of determinants influencing such states, and the application of this knowledge to control the health problems” (Dictionary of Epidemiology, Porta 2008). It covers a very broad and diverse line of research:
- experimental vs observational studies
- within the observational studies:
- exploratory vs descriptive
- exposure vs outcome oriented The collected data can also be very diverse, and include questionnaires, forms, medical device outcomes, biological data, etc.
Epidemiological studies are generally done in one of two settings: primary (based on newly collected data) or secondary (using existing databases).
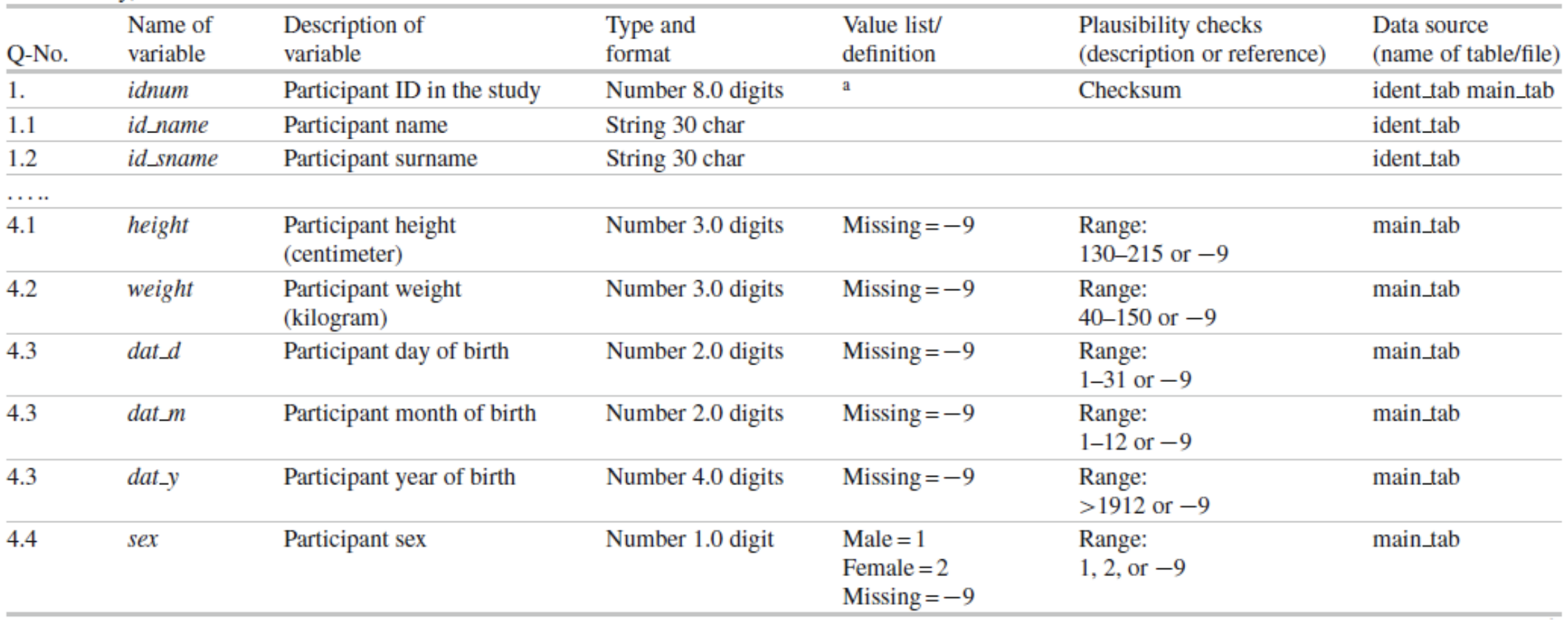
Generally a codebook or data dictionary that describes all data sources (collected, derived, transformed, …). An example of a data dictionary is provided below (taken from Ahrens, W. et al. (2014): Handbook of epidemiology. Table 27.2).
2c. DNA sequencing and genotyping
The importance of DNA sequencing and genotyping is steadily increasing within research and health care. In genotyping, one reads the nucleotides at specific positions in the genome to check if the patient has an allele that for example constitutes a higher risk to certain diseases, or that indicates higher or lower sensitivity to certain medication.
For example, mutations in the BRCA1 and BRCA2 genes change a person’s chance of getting breast cancer (see http://arup.utah.edu/database/BRCA/Variants/BRCA2.php for a list of possible mutations in BRCA2 and their pathogenicity). One of the many harmful mutations is a mutation at position 32,316,517 on chromosome 13 (in exon 2 of BRCA2) that changes a C to an A, resulting in a stop codon.
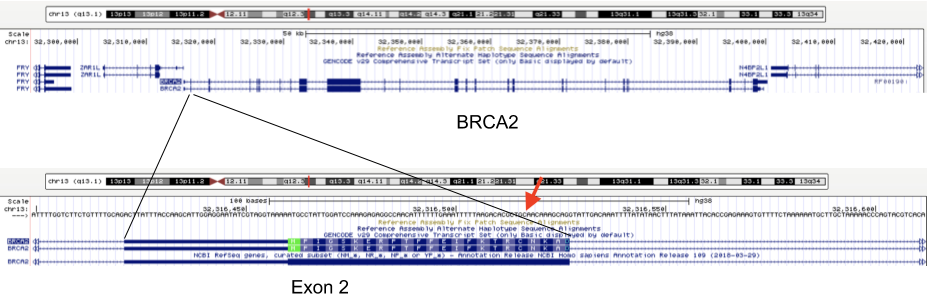
Genotyping results therefore contain information on:
- the individual
- the polymorphism (i.e. identifying what nucleotide is changed) position in the genome (i.e. chr13 position 32,316,517)
- the allele (i.e. C or A)
For each, additional information can be recorded:
- for the individual: their name, ethnicity
- for the polymorphism: the unique identifier in a central database (in this case: rs878853592), the chromosome (chr13), the position (32,316,517), the allele that occurs in healthy individuals (i.e. C)
An example genotype table:

This table contains the information for 3 polymorphisms (called rs12345, rs98765 and rs28465) for 2 individuals (individual_A and individual_B). Typically, thousands of polymorphisms are recorded for thousands of individuals.
A particular type of polymorphism is the single nucleotide polymorphism (SNP), which will be why tables below will be called snps.
3. Relational databases
There is a wide variety of database systems to store data, but the most-used in the relational database management system (RDBMS). These basically consist of tables that contain rows (which represent instance data) and columns (representing properties of that data). Any table can be thought of as an Excel-sheet.
Relational databases are the most wide-spread paradigm used to store data. They use the concept of tables with each row containing an instance of the data, and each column representing different properties of that instance of data. Different implementations exist, include ones by Oracle and MySQL. For many of these (including Oracle and MySQL), you need to run a database server in the background. People (or you) can then connect to that server via a client. In this session, however, we’ll use SQLite3. SQLite is used by Firefox, Chrome, Android, Skype, …
3.1 SQLite
The relational database management system (RDBMS) that we will use is SQLite. It is very lightweight and easy to set up.
Using SQLite on the linux command line
To create a new database that you want to give the name ‘new_database.sqlite’, just call sqlite3 with the new database name. sqlite3 new_database.sqlite The name of that file does not have to end with .sqlite, but it helps you to remember that this is an SQLite database. If you add tables and data in that database and quit, the data will automatically be saved.
There are two types of commands that you can run within SQLite: SQL commands (the same as in any other relational database management system), and SQLite-specific commands. The latter start with a period, and do not have a semi-colon at the end, in contrast to SQL commands (see later).
Some useful commands:
.help=> Returns a list of the SQL-specific commands.tables=> Returns a list of tables in the database.schema=> Returns the schema of all tables.header on=> Add a header line in any output.mode column=> Align output data in columns instead of output as comma-separated values.quit
Using DB Browser for SQLite
If you like to use a graphical user interface (or don’t work on a linux or OSX computer), you can use the DB Browser for SQLite which you can download here.
Note: In all code snippets that follow below, the sqlite> at the front represents the sqlite prompt, and should not be typed in…
4. Developing the database schema
We’ll look into two examples to guide us through developing a good database schema. The database schema is basically the description of what the database looks like: what are the names of the tables, what are the columns in those tables, and how are these connected between tables?
4.1 A student database
The simplest version
Let’s say we want to store which students follow the S&DM course. We want to keep track of their first name, last name, student ID, and whether or not they follow the course. This should allow for some easy queries, such as listing all people who take the course, or returning the number of people who do so. In this case, a flat database would suffice; i.e. a single table can hold all information.
| first_name | last_name | student_id | takes_course |
|---|---|---|---|
| Martin | Van Deun | S0001 | Y |
| Sarah | Smith | S0002 | Y |
| Mary | Kopals | S0003 | N |
| … | … | … | … |
A slightly less simple setting
Consider that we want to store which students follow which courses in MSc Statistics. So we’d like to keep:
- first name, last name, student ID
- courses a student takes (CPS, LinMod, S&DM, …)
This should allow for queries e.g. to find out which people follow a particular course, the average number of courses a student takes, etc.
Let’s take the same approach as above, and we simply add a column for each course.
| first_name | last_name | student_id | takes_GLM | takes_SDM | takes_CPS | … | takes_LDA |
|---|---|---|---|---|---|---|---|
| Martin | Van Deun | S0001 | Y | Y | Y | … | N |
| Sarah | Smith | S0002 | Y | Y | N | … | Y |
| Mary | Kopals | S0003 | N | Y | Y | … | Y |
| … | … | … | … | … | … | … | … |
This way of working (called the wide format) does present some issues, though.
- We will end up with a huge table. Imagine there are 20 courses at UHasselt and 80 at other universities in Flanders that the student can follow. In addition, suppose there are 50 students. This would mean that we need (3 + 100)*50 = 5,150 cells to store this data.
- There can be a lot of wasted space, for example courses that nobody takes.
An alternative is to use the long format:
| first_name | last_name | student_id | takes_course |
|---|---|---|---|
| Martin | Van Deun | S0001 | REG |
| Martin | Van Deun | S0001 | ANOVA |
| Martin | Van Deun | S0001 | Bayesian |
| … | … | … | … |
| Martin | Van Deun | S0001 | LDA |
| Sarah | Smith | S0002 | REG |
| … | … | … | … |
This solves the issue of not having to store the information when a course is not taken, decreasing the number of cells needed from 5,150 to 2,000.
This is still not ideal though, as this design still suffers from a lot of redundancy: the first name, last name and student ID are provided over and over again. Imagine that we’d keep home address (street, street number, zip code, city, country) as well, that would look like this:
| first_name | last_name | student_id | street | number | zip | city | takes_course |
|---|---|---|---|---|---|---|---|
| Martin | Van Deun | S0001 | Some Street | 1 | 1234 | MajorCity | REG |
| Martin | Van Deun | S0001 | Some Street | 1 | 1234 | MajorCity | ANOVA |
| Martin | Van Deun | S0001 | Some Street | 1 | 1234 | MajorCity | Bayesian |
| … | … | … | … | … | … | … | … |
| Martin | Van Deun | S0001 | Main Street | 1 | 1234 | SmallVillage | LDA |
| Sarah | Smith | S0002 | Main Street | 1 | 1234 | SmallVillage | REG |
| … | … | … | … | … | … | … | … |
What if Martin Van Deun moves from Some Street 1 in MajorCity to Another Street 42 in AnotherCity? Then we would have to edit all the rows in this table that contain this information, which almost guarantees that you will end up with inconsistencies.
4.2 A genotype database
Let’s look at another example. Let’s say you want to store individuals and their genotypes. In Excel, you could create a sheet that looks like this with genotypes for 3 polymorphisms in 2 individuals:
| individual | ethnicity | rs12345 | rs12345_amb | chr_12345 | pos_12345 | rs98765 | rs98765_amb | chr_98765 | pos_98765 | rs28465 | rs28465_amb | chr_28465 | pos_28465 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| individual_A | caucasian | A/A | A | 1 | 12345 | A/G | R | 1 | 98765 | G/T | K | 5 | 28465 |
| individual_B | caucasian | A/C | M | 1 | 12345 | G/G | G | 1 | 98765 | G/G | G | 5 | 28465 |
Let’s actually create this database using the sqlite DB Browser mentioned above.
We first select New database and after giving it a name, click Create table. This is where we’ll describe what the columns should be.
We create a table called genotypes with the following columns:
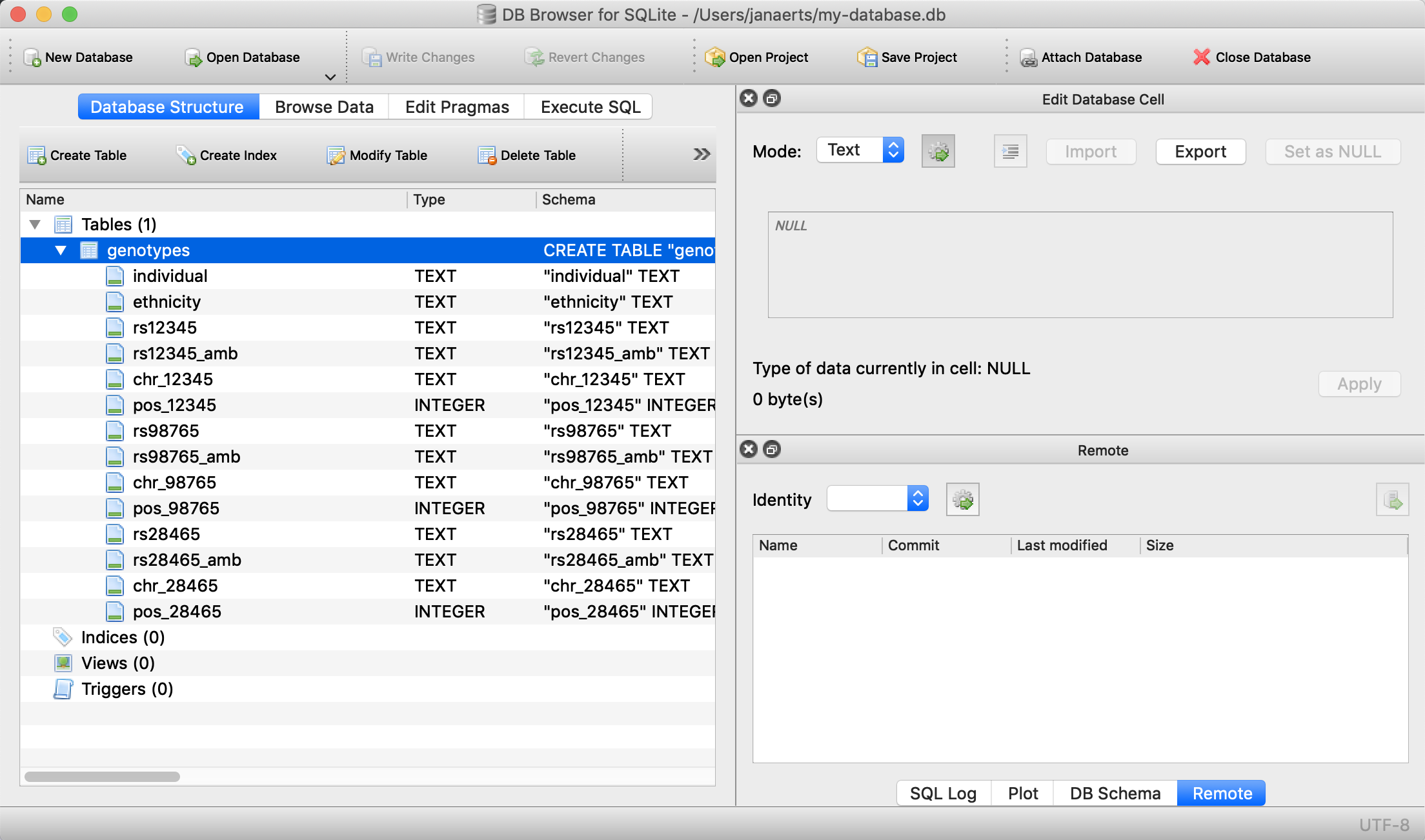
individualof typeTEXTethnicityof typeTEXTrs12345of typeTEXTrs12345_ambof typeTEXTchr_12345of typeTEXTpos_12345of typeINTEGERrs98765of typeTEXTrs98765_ambof typeTEXTchr_98765of typeTEXTpos_98765of typeINTEGERrs28465of typeTEXTrs28465_ambof typeTEXTchr_28465of typeTEXTpos_28465of typeINTEGER
We should now see the following:
This table can also be created using the following SQL command (more on this later):
CREATE TABLE genotypes (individual STRING,
ethnicity STRING,
rs12345 STRING,
rs12345_amb STRING,
chr_12345 STRING,
pos_12345 INTEGER,
rs98765 STRING,
rs98765_amb STRING,
chr_98765 STRING,
pos_98765 INTEGER,
rs28465 STRING,
rs28465_amb STRING,
chr_28465 STRING,
pos_28465 INTEGER);This only sets up the structure. We still need to actually load the data for these two individuals. We will use SQL INSERT statements for this. Click on Execute SQL, paste the code below, and run it.
INSERT INTO genotypes (individual,
ethnicity,
rs12345,
rs12345_amb,
chr_12345,
pos_12345,
rs98765,
rs98765_amb,
chr_98765,
pos_98765,
rs28465,
rs28465_amb,
chr_28465,
pos_28465)
VALUES ('individual_A','caucasian','A/A','A','1',12345, 'A/G','R','1',98765, 'G/T','K','5',28465);
INSERT INTO genotypes (individual,
ethnicity,
rs12345,
rs12345_amb,
chr_12345,
pos_12345,
rs98765,
rs98765_amb,
chr_98765,
pos_98765,
rs28465,
rs28465_amb,
chr_28465,
pos_28465)
VALUES ('individual_B','caucasian','A/C','M','1',12345, 'G/G','G','1',98765, 'G/G','G','5',28465);
Note that every SQL command is ended with a semi-colon…
We can now check that everything is loaded by clicking on Browse Data (we’ll come back to getting data out later):
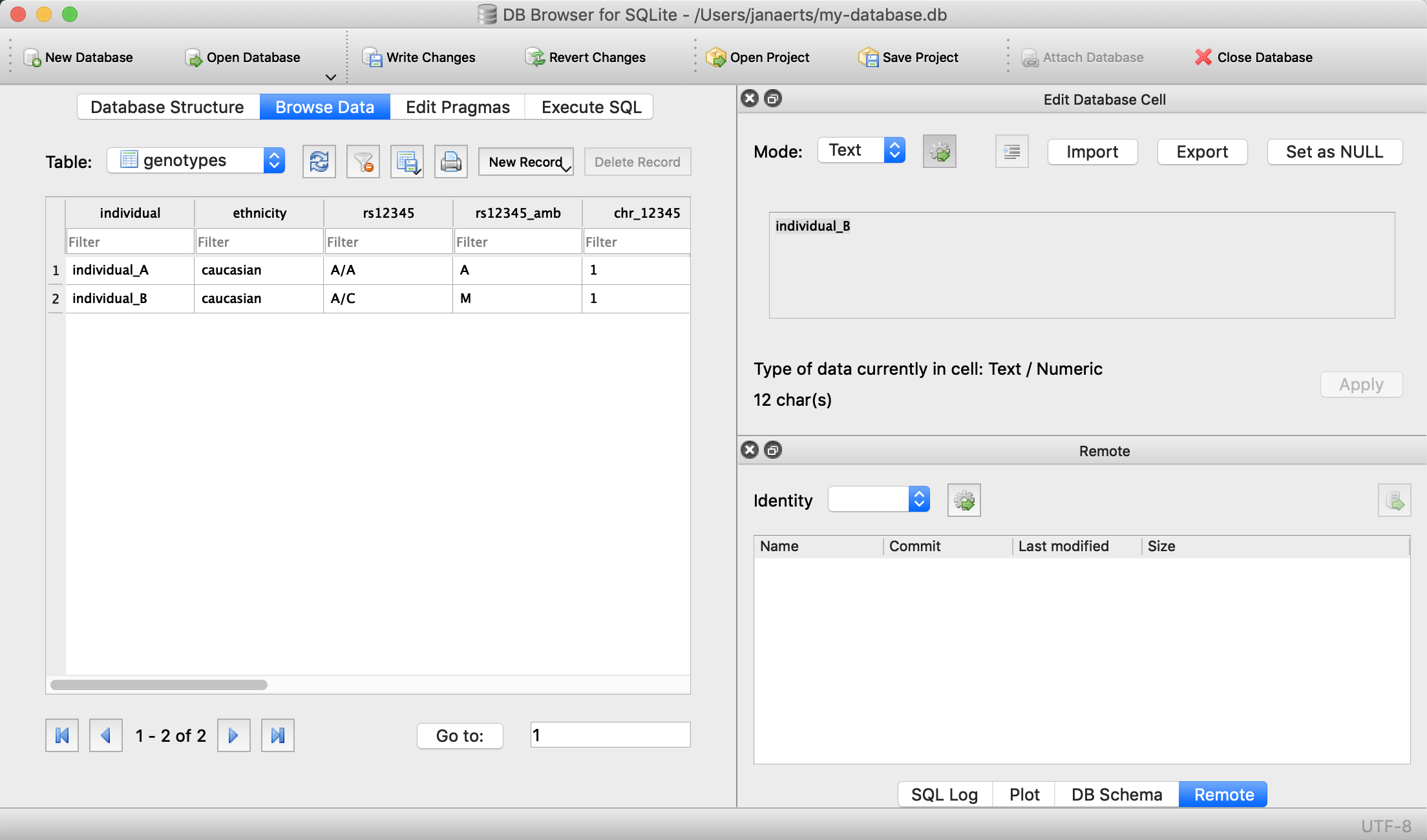
Done! For every new SNP we just add a new column, right? Wrong… In contrast to the student example above where there are - let’s say - 100 courses, a genotyping experiment can return results for millions of positions. Imaging having a table with millions of columns.
4.3 Normal forms
There are some good practices in developing relational database schemes which make it easier to work with the data afterwards. Some of these practices are represented in the “normal forms”.
First normal form
To get to the first normal form:
- Eliminate duplicative columns from the same table, i.e. convert from wide format to long format (see in the above example).
The columns rs123451, rs98765 and rs28465 are duplicates; they describe exactly the same type of thing (albeit different instances) and we need to eliminate these. And we can do that by creating new records (rows) for each SNP. In addition, each row should have a unique key. Best practices tell us to use autoincrementing integers, the primary key should contain no information in itself.
| id | individual | ethnicity | snp | genotype | genotype_amb | chromosome | position |
|---|---|---|---|---|---|---|---|
| 1 | individual_A | caucasian | rs12345 | A/A | A | 1 | 12345 |
| 2 | individual_A | caucasian | rs98765 | A/G | R | 1 | 98765 |
| 3 | individual_A | caucasian | rs28465 | G/T | K | 5 | 28465 |
| 4 | individual_B | caucasian | rs12345 | A/C | M | 1 | 12345 |
| 5 | individual_B | caucasian | rs98765 | G/G | G | 1 | 98765 |
| 6 | individual_B | caucasian | rs28465 | G/G | G | 5 | 28465 |
Create the table in the same way as above using the DB Browser with the following columns:
individualTEXTethnicityTEXTsnpTEXTgenotypeTEXTgenotype_ambSTRINGchromosomeTEXTpositionINTEGER
… or use the command line:
DROP TABLE genotypes;
CREATE TABLE genotypes (id INTEGER PRIMARY KEY, individual STRING, ethnicity STRING, snp STRING, genotype STRING, genotype_amb STRING, chromosome STRING, position INTEGER);Note that in this case we do have to define the id column ourselves, whereas the DB Browser creates a rowid column automatically.
INSERT INTO genotypes (individual, ethnicity, snp, genotype, genotype_amb, chromosome, position)
VALUES ('individual_A','caucasian','rs12345','A/A','A','1',12345);
INSERT INTO genotypes (individual, ethnicity, snp, genotype, genotype_amb, chromosome, position)
VALUES ('individual_A','caucasian','rs98765','A/G','R','1',98765);
INSERT INTO genotypes (individual, ethnicity, snp, genotype, genotype_amb, chromosome, position)
VALUES ('individual_A','caucasian','rs28465','G/T','K','1',28465);
INSERT INTO genotypes (individual, ethnicity, snp, genotype, genotype_amb, chromosome, position)
VALUES ('individual_B','caucasian','rs12345','A/C','M','1',12345);
INSERT INTO genotypes (individual, ethnicity, snp, genotype, genotype_amb, chromosome, position)
VALUES ('individual_B','caucasian','rs98765','G/G','G','1',98765);
INSERT INTO genotypes (individual, ethnicity, snp, genotype, genotype_amb, chromosome, position)
VALUES ('individual_B','caucasian','rs28465','G/G','G','1',28465);The fact that id is defined as INTEGER PRIMARY KEY makes it increment automatically if not defined specifically. So loading data without explicitly specifying the value for id automatically takes care of everything.
The same goes for rowid. In the explanations and code below, replace id with rowid if you used the DB Browser instead of the command line to create the tables.
Second normal form
There is still a lot of duplication in this data. In record 1 we see that individual_A is of Caucasian ethnicity; a piece of information that is duplicated in records 2 and 3. The same goes for the positions of the SNPs. In records 1 and 4 we can see that the SNP rs12345 is located on chromosome 1 at position 12345. But what if afterwards we find an error in our data, and rs12345 is actually on chromosome 2 instead of 1? In a table as the one above we would have to look up all these records and change the value from 1 to 2. Enter the second normal form:
- Remove subsets of data that apply to multiple rows of a table and place them in separate tables.
- Create relationships between these new tables and their predecessors through the use of foreign keys.
So how could we do that for the table above? Each row contains 3 different types of things: information about an individual (i.c. name and ethnicity), a SNP (i.c. the accession number, chromosome and position), and a genotype linking those two together (the genotype column, and the column containing the IUPAC ambiguity code for that genotype). To get to the second normal form, we need to put each of these in a separate table:
- The name of each table should be plural (not mandatory, but good practice).
- Each table should have a primary key, ideally named
id. Different tables can contain columns that have the same name; column names should be unique within a table, but can occur across tables. - The individual column is renamed to name, and snp to accession.
- In the genotypes table, individuals and SNPs are linked by referring to their primary keys (as used in the individuals and snps tables). Again best practice: if a foreign key refers to the id column in the individuals table, it should be named individual_id (note the singular).
- The foreign keys individual_id and snp_id in the genotypes table must be of the same type as the id columns in the individuals and snps tables, respectively.
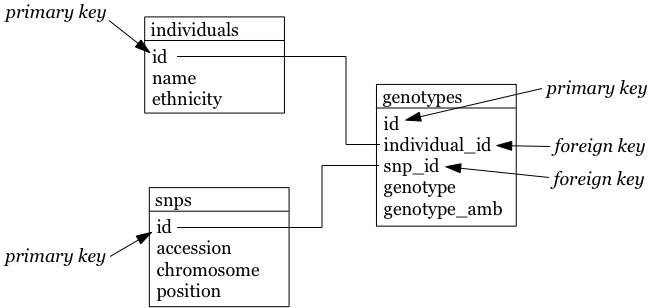
The individuals table:
| id | name | ethnicity |
|---|---|---|
| 1 | individual_A | caucasian |
| 2 | individual_B | caucasian |
The snps table:
| id | accession | chromosome | position |
|---|---|---|---|
| 1 | rs12345 | 1 | 12345 |
| 2 | rs98765 | 1 | 98765 |
| 3 | rs28465 | 5 | 28465 |
The genotypes table:
| id | individual_id | snp_id | genotype | genotype_amb |
|---|---|---|---|---|
| 1 | 1 | 1 | A/A | A |
| 2 | 1 | 2 | A/G | R |
| 3 | 1 | 3 | G/T | K |
| 4 | 2 | 1 | A/C | M |
| 5 | 2 | 2 | G/G | G |
| 6 | 2 | 3 | G/G | G |
So the snp_id foreign key 2 in row number 2 in the genotypes table links this record to the row with id primary key 2 in the snps table.
Types of table relationships
So how do you know in which table to create the foreign keys? Should there be a snp_id in the genotypes table? Or a genotype_id in the snps table? That all depends on the type of relationship between two tables. This type can be:
- one-to-one, for example an single ISBN number can be linked to a single book and vice versa.
- one-to-many, for example a single company will have many employees, but a single employee will work only for a single company
- many-to-many, for example a single book can have multiple authors and a single author can have written multiple books
One-to-many is obviously the same as many-to-one but looking at it from the other direction…
When you have a one-to-one relationship, you can actually merge that information into the same table so in the end you won’t even need a foreign key. In the book example mentioned above, you’d just add the ISBN number to the books table.
When you have a one-to-many relationship, you’d add the foreign key to the “many” table. In the example below a single company will have many employees, so you add the foreign key in the employees table.
The companies table:
| id | company_name |
|---|---|
| 1 | Big company 1 |
| 2 | Big company 2 |
| 3 | Big company 3 |
| … | … |
The employees table:
| id | name | address | company_id |
|---|---|---|---|
| 1 | John Jones | some_address, some_city | 1 |
| 2 | Jim James | another_address, some_city | 1 |
| 3 | Fred Fredricks | yet_another_address, another_city | 1 |
| … | … | … | … |
When you have a many-to-many relationship you’d typically extract that information into a new table. For the books/authors example, you’d have a single table for the books, a single table for the authors, and a separate table that links the two together. That “linking” table can also contain information that is specific for that relationship, but it does not have to. An example is the genotypes table above. There are many SNPs for a single individual, and a single SNP is measured for many individuals. That’s why we created a separate table called genotypes, which in this case has additional columns that denote the value for a single individual for a single SNP. For the books/authors example, this would be:
The books table:
| id | title | ISBN13 |
|---|---|---|
| 1 | Good Omens: The Nice and Accurate Prophecies of Agnes Nutter, Witch | 9780060853983 |
| 2 | Going Postal (Discworld #33) | 9780060502935 |
| 3 | Small Gods (Discworld #13) | 9780552152976 |
| 4 | The Stupidest Angel: A Heartwarming Tale of Christmas Terror | 9780060842352 |
| … | … | … |
The authors table:
| id | name |
|---|---|
| 1 | Terry Pratchett |
| 2 | Christopher Moore |
| 3 | Neil Gaiman |
| … | … |
The author2book table:
| id | author_id | book_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 3 | 1 |
| 3 | 1 | 2 |
| 4 | 1 | 3 |
| 5 | 2 | 4 |
| … | … | … |
The information in these tables says that:
- Terry Pratchett and Neil Gaiman co-wrote “Good Omens”
- Terry Pratchett wrote “Going Postal” and “Small Gods” by himself
- Christopher Moore was the single authors of “The Stupidest Angel”
Now back to our individuals and their genotypes…
To generate the individuals, snps and genotypes tables of the second normal form, use the DB Browser again or do this command line. You can get the information you need to create the individual columns from the piece of code below, taking into account:
- that you do not have to create the
idcolumn - that you will have to select
TEXTin the dropdown box instead ofSTRING
DROP TABLE individuals;
DROP TABLE snps;
DROP TABLE genotypes;
CREATE TABLE individuals (id INTEGER PRIMARY KEY, name STRING, ethnicity STRING);
CREATE TABLE snps (id INTEGER PRIMARY KEY, accession STRING, chromosome STRING, position INTEGER);
CREATE TABLE genotypes (id INTEGER PRIMARY KEY, individual_id INTEGER, snp_id INTEGER, genotype STRING, genotype_amb STRING);To then load the data:
INSERT INTO individuals (name, ethnicity) VALUES ('individual_A','caucasian');
INSERT INTO individuals (name, ethnicity) VALUES ('individual_B','caucasian');
INSERT INTO snps (accession, chromosome, position) VALUES ('rs12345','1',12345);
INSERT INTO snps (accession, chromosome, position) VALUES ('rs98765','1',98765);
INSERT INTO snps (accession, chromosome, position) VALUES ('rs28465','5',28465);
INSERT INTO genotypes (individual_id, snp_id, genotype, genotype_amb) VALUES (1,1,'A/A','A');
INSERT INTO genotypes (individual_id, snp_id, genotype, genotype_amb) VALUES (1,2,'A/G','R');
INSERT INTO genotypes (individual_id, snp_id, genotype, genotype_amb) VALUES (1,3,'G/T','K');
INSERT INTO genotypes (individual_id, snp_id, genotype, genotype_amb) VALUES (2,1,'A/C','M');
INSERT INTO genotypes (individual_id, snp_id, genotype, genotype_amb) VALUES (2,2,'G/G','G');
INSERT INTO genotypes (individual_id, snp_id, genotype, genotype_amb) VALUES (2,3,'G/G','G');Third normal form
In the third normal form, we try to eliminate unnecessary data from our database; data that could be calculated based on other things that are present. In our example table genotypes, the genotype and genotype_amb columns basically contain the same information, just using a different encoding. We could (should) therefore remove one of these. This is similar to having a column with country names (e.g. ‘Belgium’) and one with country codes (e.g. ‘Bel’) in the individuals table: you’d want to remove one of those.
Our final individuals table would look like this:
| id | name | ethnicity |
|---|---|---|
| 1 | individual_A | caucasian |
| 2 | individual_B | caucasian |
The snps table:
| id | accession | chromosome | position |
|---|---|---|---|
| 1 | rs12345 | 1 | 12345 |
| 2 | rs98765 | 1 | 98765 |
| 3 | rs28465 | 5 | 28465 |
The genotypes table:
| id | individual_id | snp_id | genotype_amb |
|---|---|---|---|
| 1 | 1 | 1 | A |
| 2 | 1 | 2 | R |
| 3 | 1 | 3 | K |
| 4 | 2 | 1 | M |
| 5 | 2 | 2 | G |
| 6 | 2 | 3 | G |
To know what your database schema looks like, you can issue the .schema command in sqlite3. .tables gives you a list of the tables that are defined. If you’re using the DB Browser tool, click on Database Structure.
4.4 Types of relationships between tables
Relationships between tables are often categorised as:
- one-to-one: one row in one table is linked to exactly one row in another table (e.g. ISBN number in first table to book in second table)
- one-to-many: one row in a table can be linked to 0, 1 or multiple rows in another table (e.g. a mother can have 1 or more children)
- many-to-many: 0, 1 or many rows in one table can be linked to 0, 1 or many rows in another (e.g. links between books and authors)



4.5 Other best practices
There are some additional guidelines that you can use in creating your database schema, although different people use different guidelines. Everyone ends up with their own approach. What I do:
- No capitals in table or column names
- Every table name is plural (e.g.
genes) - The primary key of each table should be
id - Any foreign key should be the singular of the table name, plus “_id”. So for example, a genotypes table can have a sample_id column which refers to the id column of the samples table.
In some cases, I digress from the rule of “every table name is plural”, especially if a table is really meant to link to other tables together. A table genotypes which has an id, sample_id, snp_id, and genotype could e.g. also be called sample2snp.
4.6 Referential integrity
In a SQL database, it is important that there are no tables that contain a foreign key which cannot be resolved. For example in the genotypes table above, there should not be a row where the individual_id is 9 because there does not exist a record in the individuals table with an id of 9.
This might occur when you originally have that record in the individuals table, but removed it (either accidentally or on purpose). Large database management systems like Oracle actually will complain when you try to do that, and do not allow you to remove that row before any row referencing it in another table is removed first. As SQLite is lightweight, however, you will have to take care of this yourself.
This also means that when loading data, you should first load the individuals and snps tables, and only load the genotypes table afterwards, because the ids of the specific individuals and snps is otherwise not known yet.
4.7 Indices
There might be columns that you will often use for filtering. For example, you expect to regularly run queries that include a filter on ethnicity. To speed things up you can create an index on that column.
CREATE INDEX idx_ethnicity ON genotypes (ethnicity);4.8 Conclusion: key concepts
So some key concepts in relational database design:
- relational database = collection of tables
- table = collection of columns (attributes) describing a relation
- tuple = row of data in the table
- attribute = a characteristic or descriptor of tuples
- primary key = a unique identifier for a tuple. This can be a single column, or a collection of columns.
5. SQL - Structured Query Language
Any interaction with data in RDBMS can happen through the Structured Query Language (SQL): create tables, insert data, search data, … There are two subparts of SQL:
DDL - Data Definition Language:
CREATE DATABASE test;
CREATE TABLE snps (id INT PRIMARY KEY AUTOINCREMENT, accession STRING, chromosome STRING, position INTEGER);
ALTER TABLE...
DROP TABLE snps;For examples: see above.
DML - Data Manipulation Language:
SELECT
UPDATE
INSERT
DELETESome additional functions are:
DISTINCT
COUNT(*)
COUNT(DISTINCT column)
MAX(), MIN(), AVG()
GROUP BY
UNION, INTERSECTWe’ll look closer at getting data into a database and then querying it, using these four SQL commands.
5.1 Getting data in
INSERT INTO
There are several ways to load data into a database. The method used above is the most straightforward but inadequate if you have to load a large amount of data.
It’s basically:
INSERT INTO <table_name> (<column_1>, <column_2>, <column_3>)
VALUES (<value_1>, <value_2>, <value_3>);Importing a datafile
But this becomes an issue if you have to load 1,000s of records. Luckily, it’s possible to load data from a comma-separated file straight into a table. Suppose you want to load 3 more individuals, but don’t want to type the insert commands straight into the sql prompt. Create a file (e.g. called data.csv) that looks like this:
individual_C,african individual_D,african individual_C,asian
Using DB Browser
Using the DB Browser, you can just go to File -> Import -> Table from CSV File.... Note that when you import a file like that, the system will automatically create the rowid column that will serve as the primary key.
On the command line
SQLite contains a .import command to load this type of data. Syntax: .import <file> <table>. So you could issue:
.separator ','
.import data.csv individualsAargh… We get an error!
Error: data.tsv line 1: expected 3 columns of data but found 2
This is because the table contains an ID column that is used as primary key and that increments automatically. Unfortunately, SQLite cannot work around this issue automatically. One option is to add the new IDs to the text file and import that new file. But we don’t want that, because it screws with some internal counters (SQLite keeps a counter whenever it autoincrements a column, but this counter is not adjusted if you hardwire the ID). A possible workaround is to create a temporary table (e.g. individuals_tmp) without the id column, import the data in that table, and then copy the data from that temporary table to the real individuals.
.schema individuals
CREATE TABLE individuals_tmp (name STRING, ethnicity STRING);
.separator ','
.import data.csv individuals_tmp
INSERT INTO individuals (name, ethnicity) SELECT * FROM individuals_tmp;
DROP TABLE individuals_tmp;Your individuals table should now look like this (using SELECT * FROM individuals;):
| id | name | ethnicity |
|---|---|---|
| 1 | individual_A | caucasian |
| 2 | individual_B | caucasian |
| 3 | individual_C | african |
| 4 | individual_D | african |
| 5 | individual_E | asian |
5.2 Getting data out
It may seem counter-intuitive to first break down the data into multiple tables using the normal forms as described above, in order to having to combine them afterwards again in a SQL query. The reason for this is simple: it allows you to ask the data any question much more easily, instead of being restricted to the format of the original data.
Queries
Why do we need queries? Because natural languages (e.g. English) are too vague: with complex questions, it can be hard to verify that the question was interpreted correctly, and that the answer we received is truly correct. The Structured Query Language (SQL) is a standardised system so that users and developers can learn one method that works on (almost) any system.
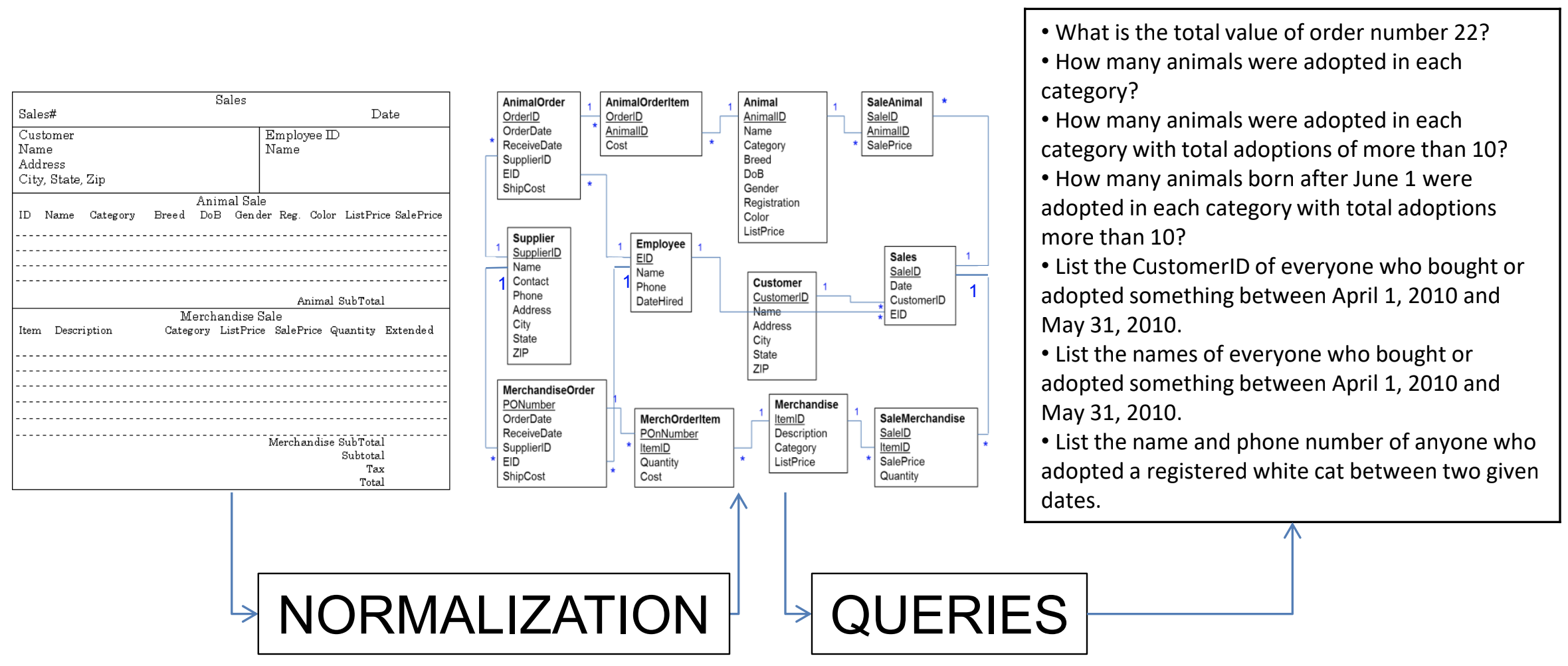
In order to write your queries, you’ll need to know what the database looks like. A relationship diagram including tables, columns and relations is very helpful here. See for example this relationship diagram for a pet store.
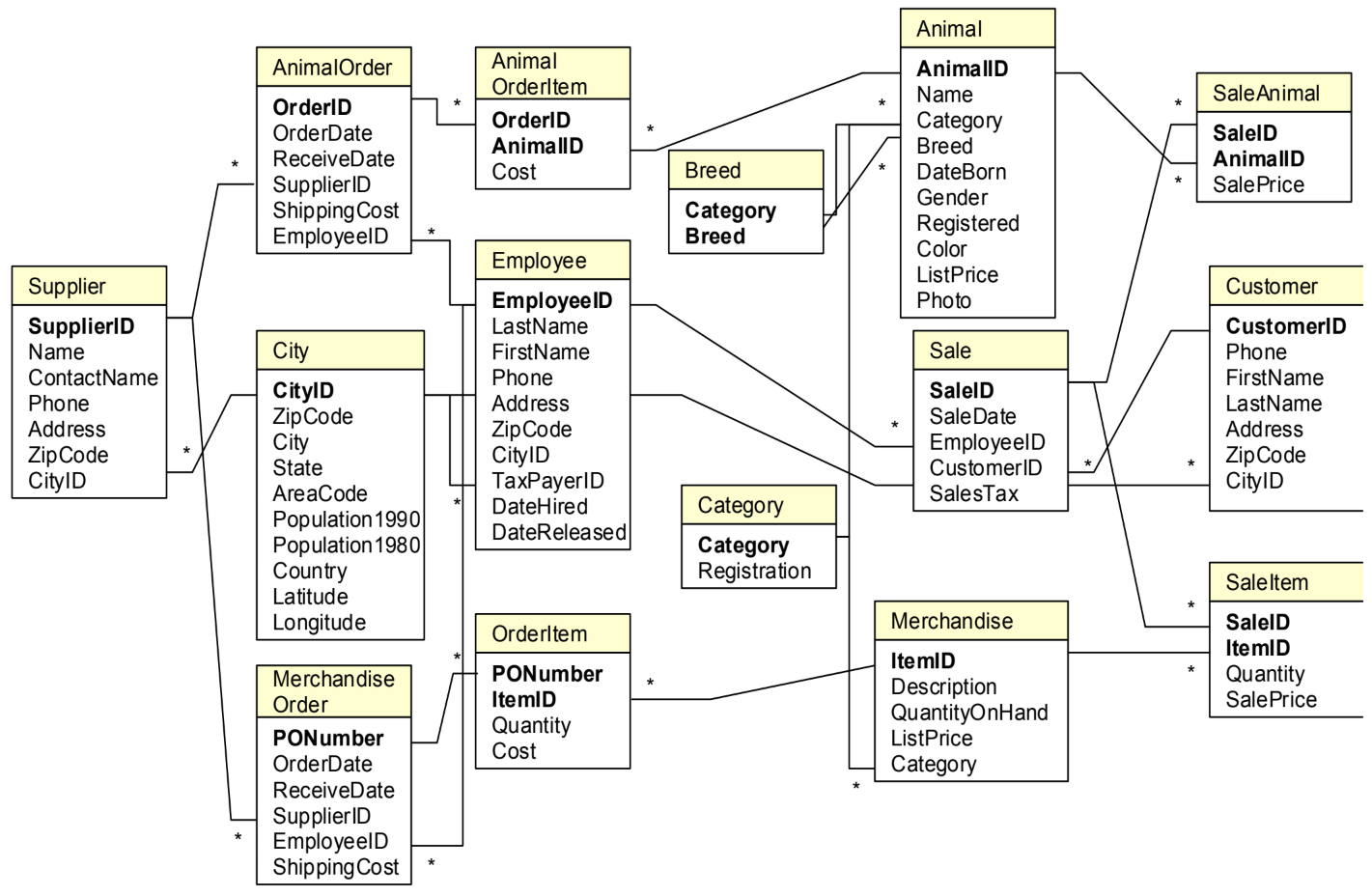
Questions that we can ask the database include:
- Which animals were born after August 1?
- List the animals by category and breed.
- List the categories of animals that are in the Animal list.
- Which dogs have a donation value greater than $250?
- Which cats have black in their color?
- List cats excluding those that are registered or have red in their color.
- List all dogs who are male and registered or who were born before 01-June-2010 and have white in their color.
- What is the extended value (price * quantity) for sale items on sale 24?
- What is the average donation value for animals?
- What is the total value of order number 22?
- How many animals were adopted in each category?
- How many animals were adopted in each category with total adoptions of more than 10?
- How many animals born after June 1 were adopted in each category with total adoptions more than 10?
- List the CustomerID of everyone who bought or adopted something between April 1, 2010 and May 31, 2010.
- List the names of everyone who bought or adopted something between April 1, 2010 and May 31, 2010.
- List the name and phone number of anyone who adopted a registered white cat between two given dates.
Similarly, we already drew the relationship diagram for the genotypes.
Questions that we can ask:
- What is the number of individuals for each ethnicity?
- How many SNPs are there per chromosome?
- Approximately how long is chromosome 22 (by looking at the maximum SNP position)?
- What are the most/least common genotypes?
- …
Single tables
It is very simple to query a single table. The basic syntax is:
SELECT <column_name1, column_name2> FROM <table_name> WHERE <conditions>;If you want to see all columns, you can use “*” instead of a list of column names, and you can leave out the WHERE clause. The simplest query is therefore SELECT * FROM <table_name>;. So the <column_name1, column_name2> slices the table vertically while the WHERE clause slices it horizontally.
Data can be filtered using a WHERE clause. For example:
SELECT * FROM individuals WHERE ethnicity = 'african';
SELECT * FROM individuals WHERE ethnicity = 'african' OR ethnicity = 'caucasian';
SELECT * FROM individuals WHERE ethnicity IN ('african', 'caucasian');
SELECT * FROM individuals WHERE ethnicity != 'asian';What if you can’t remember if the ethnicity was stored capitalised or not? In other words: was it ‘caucasian’ or ‘Caucasian’? One way of approaching this is using the LIKE keyword. It behaves the same as ==, but you can use wildcards (i.c. %) that can represent any character. For example, the following two are almost the same:
SELECT * FROM individuals WHERE ethnicity == 'Caucasian' OR ethnicity == 'caucasian';
SELECT * FROm individuals WHERE ethnicity LIKE '%aucasian';I say “almost” the same, because the % can stand for more than one character. A WHERE ethnicity LIKE '%sian' would therefore return those individuals who are “Caucasian”, “caucasian”, “Asian” and “asian”.
You often just want to see a small subset of data just to make sure that you’re looking at the right thing. In that case: add a LIMIT clause to the end of your query, which has the same effect as using head on the linux command-line. Please always do this if you don’t know what your table looks like because you don’t want to send millions of lines to your screen.
SELECT * FROM individuals LIMIT 5;
SELECT * FROM individuals WHERE ethnicity = 'caucasian' LIMIT 1;If you just want know the number of records that would match your query, use COUNT(*):
SELECT COUNT(*) FROM individuals WHERE ethnicity = 'african';Using the GROUP BY clause you can aggregate data. For example:
SELECT ethnicity, COUNT(*) from individuals GROUP BY ethnicity;Combining tables
In the second normal form we separated several aspects of the data in different tables. Ultimately, we want to combine that information of course. This is where the primary and foreign keys come in. Suppose you want to list all different SNPs, with the alleles that have been found in the population:
SELECT individual_id, snp_id, genotype_amb FROM genotypes;This isn’t very informative, because we get the uninformative numbers for SNPs instead of SNP accession numbers. To run a query across tables, we have to call both tables in the FROM clause:
SELECT individuals.name, snps.accession, genotypes.genotype_amb FROM individuals, snps, genotypes;| name | accession | genotype_amb |
|---|---|---|
| individual_A | rs12345 | A |
| individual_A | rs12345 | R |
| individual_A | rs12345 | K |
| individual_A | rs12345 | M |
| individual_A | rs12345 | G |
| individual_A | rs12345 | G |
| individual_A | rs98765 | A |
| individual_A | rs98765 | R |
| individual_A | rs98765 | K |
| individual_A | rs98765 | M |
| individual_A | rs98765 | G |
| individual_A | rs98765 | G |
| individual_A | rs28465 | A |
| individual_A | rs28465 | R |
| individual_A | rs28465 | K |
| individual_A | rs28465 | M |
| individual_A | rs28465 | G |
| individual_A | rs28465 | G |
| individual_B | rs12345 | A |
| individual_B | rs12345 | R |
| individual_B | rs12345 | K |
| individual_B | rs12345 | M |
| individual_B | rs12345 | G |
| individual_B | rs12345 | G |
| individual_B | rs98765 | A |
| individual_B | rs98765 | R |
| individual_B | rs98765 | K |
| individual_B | rs98765 | M |
| individual_B | rs98765 | G |
| individual_B | rs98765 | G |
| individual_B | rs28465 | A |
| individual_B | rs28465 | R |
| individual_B | rs28465 | K |
| individual_B | rs28465 | M |
| individual_B | rs28465 | G |
| individual_B | rs28465 | G |
Wait… This can’t be correct: we get 36 rows back instead of the 6 that we expected. This is because all combinations are made between all rows of each table. We have to put some constraints on the rows that are returned.
SELECT individuals.name, snps.accession, genotypes.genotype_amb
FROM individuals, snps, genotypes
WHERE individuals.id = genotypes.individual_id
AND snps.id = genotypes.snp_id;| name | accession | genotype_amb |
|---|---|---|
| individual_A | rs12345 | A |
| individual_A | rs98765 | R |
| individual_A | rs28465 | K |
| individual_B | rs12345 | M |
| individual_B | rs98765 | G |
| individual_B | rs28465 | G |
What happens here?
- The individuals, snps and genotypes tables are referenced in the FROM clause.
- In the SELECT clause, we tell the query what columns to return. We prepend the column names with the table name, to know what column we actually mean (snps.id is a different column from individuals.id).
- In the WHERE clause, we actually provide the link between the tables: the value for snp_id in the genotypes table should correspond with the id column in the snps table. This is the part that solves the above issue of returning all those nonsense rows. Imagine that we’d ask the id’s themselves as well, then we’d get the list below. From that list, we can then filter the rows that adhere to the constraints we set.
SELECT individuals.id, genotypes.individual_id, snps.id, genotypes.snp_id, individuals.name, snps.accession, genotypes.genotype_amb
FROM individuals, snps, genotypes;| individual.id | genotypes.individual_id | snps.id | genotypes.snp_id | name | accession | genotype_amb |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | individual_A | rs12345 | A |
| 1 | 1 | -1- | -2- | individual_A | rs12345 | R |
| 1 | 1 | -1- | -3- | individual_A | rs12345 | K |
| -1- | -2- | 1 | 1 | individual_A | rs12345 | M |
| -1- | -2- | -1- | -2- | individual_A | rs12345 | G |
| -1- | -2- | -1- | -3- | individual_A | rs12345 | G |
| 1 | 1 | -2- | -1- | individual_A | rs98765 | A |
| 1 | 1 | 2 | 2 | individual_A | rs98765 | R |
| 1 | 1 | -2- | -3- | individual_A | rs98765 | K |
| -1- | -2- | -2- | -1- | individual_A | rs98765 | M |
| -1- | -2- | 2 | 2 | individual_A | rs98765 | G |
| -1- | -2- | -2- | -3- | individual_A | rs98765 | G |
| 1 | 1 | -3- | -1- | individual_A | rs28465 | A |
| 1 | 1 | -3- | -2- | individual_A | rs28465 | R |
| 1 | 1 | 3 | 3 | individual_A | rs28465 | K |
| -1- | -2- | -3- | -1- | individual_A | rs28465 | M |
| -1- | -2- | -3- | -2- | individual_A | rs28465 | G |
| -1- | -2- | 3 | 3 | individual_A | rs28465 | G |
| -2- | -1- | 1 | 1 | individual_B | rs12345 | A |
| -2- | -1- | -1- | -2- | individual_B | rs12345 | R |
| -2- | -1- | -1- | -3- | individual_B | rs12345 | K |
| 2 | 2 | 1 | 1 | individual_B | rs12345 | M |
| … | … | … | … | … | … | … |
Having to type the table names in front of the column names can become tiresome. We can however create aliases like this:
SELECT i.name, s.accession, g.genotype_amb
FROM individuals i, snps s, genotypes g
WHERE i.id = g.individual_id
AND s.id = g.snp_id;JOIN
Sometimes, though, we have to join tables in a different way. Suppose that our snps table contains SNPs that are nowhere mentioned in the genotypes table, but we still want to have them mentioned in our output:
INSERT INTO snps (accession, chromosome, position) VALUES ('rs11223','2',11223);If we run the following query:
SELECT s.accession, s.chromosome, s.position, g.genotype_amb
FROM snps s, genotypes g
WHERE s.id = g.snp_id
ORDER BY s.accession, g.genotype_amb;We get the following output:
| chromosome | position | accession | genotype_amb |
|---|---|---|---|
| 1 | 12345 | rs12345 | A |
| 1 | 12345 | rs12345 | M |
| 1 | 98765 | rs98765 | G |
| 1 | 98765 | rs98765 | R |
| 5 | 28465 | rs28465 | G |
| 5 | 28465 | rs28465 | K |
But we actually want to have rs11223 in the list as well. Using this approach, we can’t because of the WHERE s.id = g.snp_id clause. The solution to this is to use an explicit join. To make things complicated, there are several types: inner and outer joins. In principle, an inner join gives the result of the intersect between two tables, while an outer join gives the results of the union. What we’ve been doing up to now is look at the intersection, so the approach we used above is equivalent to an inner join:
SELECT s.accession, g.genotype_amb
FROM snps s INNER JOIN genotypes g ON s.id = g.snp_id
ORDER BY s.accession, g.genotype_amb;gives:
| accession | genotype_amb |
|---|---|
| rs12345 | A |
| rs12345 | M |
| rs28465 | G |
| rs28465 | K |
| rs98765 | G |
| rs98765 | R |
A left outer join returns all records from the left table, and will include any matches from the right table:
SELECT s.accession, g.genotype_amb
FROM snps s LEFT OUTER JOIN genotypes g ON s.id = g.snp_id
ORDER BY s.accession, g.genotype_amb;gives:
| accession | genotype_amb |
|---|---|
| rs11223 | |
| rs12345 | A |
| rs12345 | M |
| rs28465 | G |
| rs28465 | K |
| rs98765 | G |
| rs98765 | R |
(Notice the extra line for rs11223!)
A full outer join, finally, return all rows from the left table, and all rows from the right table, matching any rows that should be.
Export to file
Often you will want to export the output you get from an SQL-query to a file (e.g. CSV) on your operating system so that you can use that data for external analysis in R or for visualisation. This is easy to do. Suppose that we want to export the first 5 lines of the snps table into a file called 5_snps.csv.
Using DB Browser
There’s a button for that…
On the command line
You do that like this:
.header on
.mode csv
.once 5_snps.csv
SELECT * FROM snps LIMIT 5;If you now exit the sqlite prompt (with .quit), you should see a file in the directory where you were that is called 5_snps.csv.
5.3 Updating and deleting data
Sometimes you will want to update or delete data in a table. The SQL code to do this uses a WHERE clause that is exactly the same as for a regular SELECT. A very important tip: first do a SELECT on your table with the WHERE clause that you’ll use for the update or deletion just to make sure that you’ll change the correct rows. When you’ve made changes to the wrong rows you won’t be able to go back (unless you use the Lambda architecture principles as we will explain in the third session).
UPDATE
Imagine that we’ve been storing the information on our individuals as above, but have not been consistent in capitalising the ethnicity. In some cases, a person can be of asian descent; in other cases he or she can be Asian. The same would go for the other ethnicities. To clean this up, let’s put everything in lower case. For argument’s sake we’ll only look at Asian here. First let’s check what we should get with a SELECT.
SELECT * FROM individuals
WHERE ethnicity == 'Asian';This will give us the rows that we will change. Are these indeed the ones? Then go forward with the update:
UPDATE individuals
SET ethnicity = 'asian'
WHERE ethnicity == 'Asian';The WHERE clause is the same. The general syntax for an update looks like this:
UPDATE <table>
SET <column> = <new value>
WHERE <conditions>;In this example the column that is updated (ethnicity) is the same as the one in the WHERE clause. This does not have to be the case. What would the following do?
UPDATE genotypes
SET genotype_amb = 'R'
WHERE genotype == 'A/G';DELETE
DELETE is similar to UPDATE but simpler: you don’t use the SET pragma. Same as with updating data, make sure that your WHERE clause is correct! Test this with a SELECT beforehand.
The general syntax:
DELETE FROM <table>
WHERE <conditions>;For example:
DELETE FROM genotypes
WHERE genotype_amb == 'N';5.4 Additional functions
LIMIT
If you only want to get the first 10 results back (e.g. to find out if your complicated query does what it should do without running the whole actual query), use LIMIT:
sqlite> SELECT * FROM snps LIMIT 2;NULL
SNPs are spread across a chromosome, and might or might not be located within a gene.

What if you want to search for the SNPs that are not in genes? Imagine that our snps table has an additional column with the gene name, like this:
| id | accession | chromosome | position | gene |
|---|---|---|---|---|
| 1 | rs12345 | 1 | 12345 | gene_A |
| 2 | rs98765 | 1 | 98765 | gene_A |
| 3 | rs28465 | 5 | 28465 | gene_B |
| 4 | rs92873 | 7 | 7382 | |
| 5 | rs10238 | 11 | 291732 | gene_C |
| 6 | rs92731 | 17 | 10283 | gene_C |
We cannot SELECT * FROM snps WHERE gene = ""; because that is searching for an empty string which is not the same as a missing value. To get to rs92873 you can issue SELECT * FROM snps WHERE gene IS NULL; or to get the rest SELECT * FROM snps WHERE GENE IS NOT NULL;. Note that it is IS NULL and not = NULL…
AND, OR
Your queries might need to combine different conditions, as we’ve already seen above:
AND: both must be trueOR: either one is trueNOT: reverse the value
SELECT * FROM snps WHERE chromosome = '1' AND position < 40000;
SELECT * FROM snps WHERE chromosome = '1' OR chromosome = '5';
SELECT * FROM snps WHERE chromosome = '1' AND NOT position < 40000;The result is affected by the order of the operations. Parentheses indicate that an operation should be performed first. Without parentheses, operations are performed left-to-right.
For example, if a = 3, b = -1 and c = 2, then:
- (( a > 4 ) AND ( b < 0 )) OR ( c > 1 ) evaluates to true
- ( a > 4 ) AND (( b < 0 ) OR ( c > 1 )) evaluates to false
De Morgan’s laws apply to SQL. The rules allow the expression of conjunctions and disjunctions purely in terms of each other via negation. For example:
NOT (A AND B)becomesNOT A OR NOT BNOT (A OR B)becomesNOT A AND NOT B
IN
The IN clause defines a set of values. It is a shortcut to combine several entries with an OR condition.
For example, instead of writing
SELECT *
FROM customer
WHERE first_name = 'Tim' OR first_name = 'David' OR first_name = 'Jay';you can use
SELECT *
FROM customer
WHERE first_name IN ('Tim', 'David', 'Jay');DISTINCT
Whenever you want the unique values in a column: use DISTINCT in the SELECT clause:
SELECT category FROM animal;| category |
|---|
| Fish |
| Dog |
| Fish |
| Cat |
| Cat |
| Dog |
| Fish |
| Dog |
| Dog |
| Dog |
| Fish |
| Cat |
| Dog |
| … |
SELECT DISTINCT category FROM animal;| distinct(category) |
|---|
| Bird |
| Cat |
| Dog |
| Fish |
| Mammal |
| Reptile |
| Spider |
DISTINCT automatically sorts the results.
ORDER BY
The order by clause allows you to, well, order your output. By default, this is in ascending order. To order from large to small, you can add the DESC tag. It is possible to order by multiple columns, for example first by chromosome and then by position;
SELECT * FROM snps ORDER BY chromosome;
SELECT * FROM snps ORDER BY accession DESC;
SELECT * FROM snps ORDER BY chromsome, position;COUNT
For when you want to count things:
SELECT COUNT(*) FROM genotypes WHERE genotype_amb = 'G';MAX(), MIN(), AVG()
…act as you would expect (only works with numbers, obviously):
SELECT MAX(position) FROM snps;Output is:
| max(position) |
|---|
| 291732 |
AS
In some cases you might want to rename the output column name. For instance, in the example above you might want to have maximum_position instead of max(position). The AS keyword can help us with that.
SELECT MAX(position) AS maximum_position FROM snps;GROUP BY
GROUP BY can be very useful in that it first aggregates data. It is often used together with COUNT, MAX, MIN or AVG:
SELECT genotype_amb, COUNT(*) FROM genotypes GROUP BY genotype_amb;
SELECT genotype_amb, COUNT(*) AS c FROM genotypes GROUP BY genotype_amb ORDER BY c DESC;| genotype_amb | c |
|---|---|
| G | 2 |
| A | 1 |
| K | 1 |
| M | 1 |
| R | 1 |
SELECT chromosome, MAX(position) FROM snps GROUP BY chromosome ORDER BY chromosome;| chromosome | MAX(position) |
|---|---|
| 1 | 98765 |
| 2 | 11223 |
| 5 | 28465 |
HAVING
Whereas the WHERE clause puts conditions on certain columns, the HAVING clause puts these on groups created by GROUP BY.
For example, given the following snps table:
| id | accession | chromosome | position | gene |
|---|---|---|---|---|
| 1 | rs12345 | 1 | 12345 | gene_A |
| 2 | rs98765 | 1 | 98765 | gene_A |
| 3 | rs28465 | 5 | 28465 | gene_B |
| 4 | rs92873 | 7 | 7382 | |
| 5 | rs10238 | 11 | 291732 | gene_C |
| 6 | rs92731 | 17 | 10283 | gene_C |
SELECT chromosome, count(*) as c
FROM snps
GROUP BY chromosome;will return
| chromosome | c |
|---|---|
| 1 | 2 |
| 5 | 1 |
| 7 | 1 |
| 11 | 1 |
| 17 | 1 |
whereas
SELECT chromosome, count(*) as c
FROM snps
GROUP BY chromosome
HAVING c > 1will return
| chromosome | c |
|---|---|
| 1 | 2 |
The HAVING clause must follow a GROUP BY, and precede a possible ORDER BY.
UNION, INTERSECT
It is sometimes hard to get the exact rows back that you need using the WHERE clause. In such cases, it might be possible to construct the output based on taking the union or intersection of two or more different queries:
SELECT * FROM snps WHERE chromosome = '1';
SELECT * FROM snps WHERE position < 40000;
SELECT * FROM snps WHERE chromosome = '1' INTERSECT SELECT * FROM snps WHERE position < 40000;| id | accession | chromosome | position |
|---|---|---|---|
| 1 | rs12345 | 1 | 12345 |
LIKE
Sometimes you want to make fuzzy matches. What if you’re not sure if the ethnicity has a capital or not?
SELECT * FROM individuals WHERE ethnicity = 'African';returns no results…
SELECT * FROM individuals WHERE ethnicity LIKE '%frican';Note that different databases use different characters as wildcard. For example: % is a wildcard for MS SQL Server representing any string, and * is the corresponding wildcard character used in MS Access. Check the documentation for the RDBMS that you’re using (sqlite, MySQL/MariaDB, MS SQL Server, MS Access, Oracle, …) for specifics.
Subqueries
As we mentioned in the beginning, the general setup of a SELECT is:
SELECT <column_names>
FROM <table>
WHERE <condition>;But as you’ve seen in the examples above, the output from any SQL query is itself basically a table. So we can actually use that output table to run another SELECT. For example:
SELECT *
FROM (
SELECT *
FROM snps
WHERE chromosome IN ('1','5'))
WHERE position < 40000;Of course, you can use UNION and INTERSECT in the subquery as well…
Another example:
SELECT COUNT(*)
FROM (
SELECT DISTINCT genotype_amb
FROM genotypes);5.5 Public bioinformatics databases
Sqlite is a light-weight system for running relational databases. If you want to make your data available to other people it’s often better to use systems such as MySQL. The data behind the Ensembl genome browser, for example, is stored in a relational database and directly accessible through SQL as well.
To access the last release of human from Ensembl: mysql -h ensembldb.ensembl.org -P 5306 -u anonymous homo_sapiens_core_70_37. To get an overview of the tables that we can query: show tables.
To access the hg19 release of the UCSC database (which is also a MySQL database): mysql --user=genome --host=genome-mysql.cse.ucsc.edu hg19.
5.6 Views
By decomposing data into different tables as we described above (and using the different normal forms), we can significantly improve maintainability of our database and make sure that it does not contain inconsistencies. But at the other hand, this means it’s a lot of hassle to look at the actual data: to know what the genotype is for SNP rs12345 in individual_A we cannot just look it up in a single table, but have to write a complicated query which joins 3 tables together. The query would look like this:
SELECT i.name, i.ethnicity, s.accession, s.chromosome, s.position, g.genotype_amb
FROM individuals i, snps s, genotypes g
WHERE i.id = g.individual_id
AND s.id = g.snp_id;Output looks like this:
| name | ethnicity | accession | chromosome | position | genotype_amb |
|---|---|---|---|---|---|
| individual_A | caucasian | rs12345 | 1 | 12345 | A |
| individual_A | caucasian | rs98765 | 1 | 98765 | R |
| individual_A | caucasian | rs28465 | 5 | 28465 | K |
| individual_B | caucasian | rs12345 | 1 | 12345 | M |
| individual_B | caucasian | rs98765 | 1 | 98765 | G |
| individual_B | caucasian | rs28465 | 5 | 28465 | G |
There is however a way to make this easier: you can create views on the data. This basically saves the whole query and gives it a name. You do this by adding CREATE VIEW some_name AS to the front of the query, like this:
CREATE VIEW v_genotypes AS
SELECT i.name, i.ethnicity, s.accession, s.chromosome, s.position, g.genotype_amb
FROM individuals i, snps s, genotypes g
WHERE i.id = g.individual_id
AND s.id = g.snp_id;You can think of this as if you had made a new table with the name v_genotypes that you can use just like any other table, for example:
SELECT *
FROM v_genotypes g
WHERE g.genotype_amb = 'R';The difference with an actual table is, however, that the result of the view is actually not stored itself. Whenever you do SELECT * FROM v_genotypes, it will actually perform the whole query in the background.
Note: to make sure that I can tell by the name if something is a table or a view, I always add a v_ in front of the name that I give to the view.
Pivot tables
In some cases, you want to violate the 1st normal form, and have different columns represent the same type of data. A typical example is when you want to analyze your data in R using a dataframe. Let’s say we have expression values for different genes in different individuals. Being good programmers, we saved this data in the database like this:
| individual | gene | expression |
|---|---|---|
| individual_A | gene_A | 2819 |
| individual_A | gene_B | 1028 |
| individual_A | gene_C | 3827 |
| individual_B | gene_A | 1928 |
| individual_B | gene_B | 999 |
| individual_B | gene_C | 1992 |
In R, you will however probably want a dataframe that looks like this:
| gene | individual_A | individual_B |
|---|---|---|
| gene_A | 2819 | 1928 |
| gene_B | 1028 | 999 |
| gene_C | 3827 | 1992 |
This is called a pivot table, and there are several ways to create these in SQLite. The method presented here is taken from http://bduggan.github.io/virtual-pivot-tables-opensqlcamp2009-talk/. To create such table (and store it in a view), you have to use group_concat and group_by:
CREATE VIEW v_pivot_expressions AS
SELECT gene,
GROUP_CONCAT(CASE WHEN individual = 'individual_A' THEN expression ELSE NULL END) AS individual_A,
GROUP_CONCAT(CASE WHEN individual = 'individual_B' THEN expression ELSE NULL END) AS individual_B
FROM expressions
GROUP BY gene;5.7 Normalisation homework
This is the assignment for homework 1. For the due date, see the website for this part of the course..
Let’s see if we can design a normalised database to hold the data for a pet shop. “Sally’s Pet Shop” sells animal care merchandise and also lets you adopt an animal. The goal is to create a database to track the store operations: sales, orders, customer tracking, and basic animal data. The input that you have are:
- sales forms
- purchase order forms for animals
- purchase order forms for merchandise
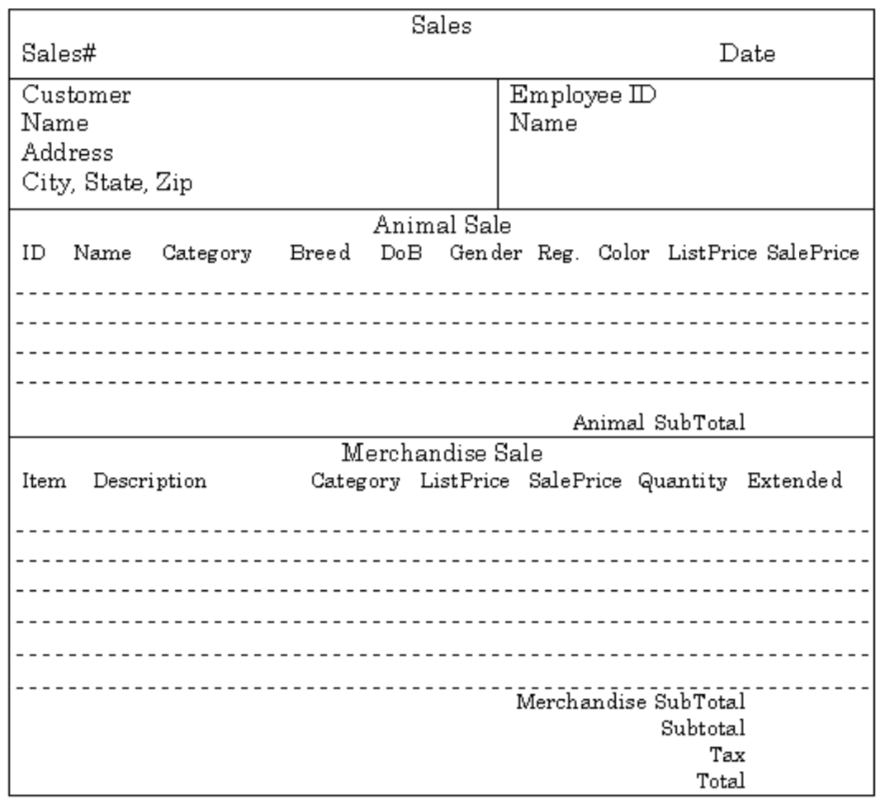
Sales
Here’s a printout of an empty sales form.
The assumptions that we take:
- there is only 1 customer per sale
- a sale is handled by 1 employee
- many customers can buy animals and merchandise
- an employee can handle many sales
- a customer can adopt several animals
- a customer can buy several merchandise items
- an animal can be adopted only once
- customer name is not unique
Animal purchase orders
Here’s an example of an empty purchase order form for animals:

Assumptions that we will take when creating the database are:
- each order is placed with 1 supplier at a time
- each order is handled by 1 employee
- a supplier can receive many orders
- an employee can handle many orders
- many animals can be ordered with 1 order
- supplier name is not unique
- animal name is not unique
Exercise: create a fully normalised database schema for this pet shop example.
6. Drawbacks of relational databases
Relational databases are great. They can be a big help in storing and organizing your data. But they are not the ideal solution in all situations.
6.1 Scalability
Relational databases are only scalable in a limited way. The fact that you try to normalise your data means that your data is distributed over different tables. Any query on that data often requires extensive joins. This is OK, until you have tables with millions of rows. A join can in that case a very long time to run.
[Although outside of the scope of this lecture.] One solution sometimes used is to go for a star-schema rather than a fully normalised schema. Or using a NoSQL database management system that is horizontally scalable (document-oriented, column-oriented or graph databases).
6.2 Modeling
Some types of information are difficult to model when using a relational paradigm. In a relational database, different records can be linked across tables using foreign keys. If you’re however really interested in the relations themselved (e.g. social graphs, protein-protein-interaction, …) you are much better of to use a real graph database (e.g. neo4j) instead of a relational database. In a graph database finding all neighbours-of-neighbours in a graph of 50 members (basically) takes as long as in a graph with 50 million members.
6.3 Drawback exercise
Suppose you want to model a social graph. People have names, and know other people. Every “know” is reciprocal (so if I know you then you know me). The data might look like this:
Tim knows Terry Tom knows Terry Terry knows Gerry Gerry knows Rik Gerry knows James James knows John Fred knows James Frits knows Fred
In table format:
| knower | knowee |
|---|---|
| Tim | Terry |
| Tom | Terry |
| Terry | Gerry |
| Gerry | Rik |
| Gerry | James |
| James | John |
| Fred | James |
| Frits | Fred |
If you really want to have this in a relational database, how would you find out who are the friends of the friends of James?