Case Study: NKI
This notebook demonstrates how lensed UMAP can be used to explore the NKI breast cancer gene-expression data set also analysed using Mapper by Lum et al. (2013). They identified several genes in the Chemokine KEGG pathway with expression differences between surviving and non-surviving patients with low ESR1 levels. We work through a visual exploration workflow to show how lensed UMAP can be used to reproduce Lum et al.’s findings.
Setup
First, we load several libraries:
[1]:
%load_ext autoreload
%autoreload 2
[2]:
import hvplot
import hvplot.pandas # noqa
import warnings
import numpy as np
import pandas as pd
import holoviews as hv
import lensed_umap as lu
from umap import UMAP
from anndata import AnnData, ImplicitModificationWarning
from scipy.stats import kstest
from sklearn.impute import KNNImputer
from holoviews.selection import link_selections
from lib.plotting import *
from matplotlib.colors import ListedColormap
_ = configure_matplotlib()
warnings.filterwarnings("ignore", lineno=151, module=r"sklearn.*")
warnings.filterwarnings("ignore", category=ImplicitModificationWarning)
The data
The NKI data set contains gene expressions and annotations for the observations and features. We load these files into a single AnnData object to facilitate working with such a structure. After loading the data, we apply the pre-processing steps described in the papers. Our interpretation of these steps may differ from the original work, introducing some differences. For example, genes and
observations with many missing values were removed, other missing values were imputed with a KNNImputer using \(k=5\). In general, though, the result should be comparable.
[3]:
def load_data():
X = pd.read_csv("./data/nki/nki_exprs.csv").T
obs = pd.read_csv("./data/nki/nki_obs.csv").drop(
columns=["samplename", "filename", "pgr", "her2"]
)
var = pd.read_csv("./data/nki/nki_var.csv")
return AnnData(X, obs, var)
def select_and_impute(df):
missing_mask = np.isnan(df.X)
missing_per_col = np.sum(missing_mask, axis=0)
missing_per_row = np.sum(missing_mask, axis=1)
df = df[:, missing_per_col < np.percentile(missing_per_col, [95])[0]]
df = df[missing_per_row < np.percentile(missing_per_row, [95])[0], :]
df.X = KNNImputer(n_neighbors=5, weights="distance").fit_transform(df.X)
return df
def select_highly_variable(df):
n_genes = 1553
variance = np.var(df.X, axis=0)
threshold = np.partition(variance, -n_genes - 1)[-n_genes - 1]
return df[:, variance > threshold].copy()
[4]:
df = load_data()
df = select_and_impute(df)
df = select_highly_variable(df)
df = df[~df.obs["e.dmfs"].isna(), :].copy()
df.obs["relapsed"] = df.obs["e.dmfs"] == 1
df
[4]:
AnnData object with n_obs × n_vars = 302 × 1553
obs: 'dataset', 'series', 'id', 'size', 'age', 'er', 'grade', 'brca.mutation', 'e.dmfs', 't.dmfs', 'node', 't.rfs', 'e.rfs', 'treatment', 'tissue', 't.os', 'e.os', 'relapsed'
var: 'probe', 'EntrezGene.ID', 'probe.name', 'Alignment.score', 'Length.of.probe', 'NCBI.gene.symbol', 'HUGO.gene.symbol', 'Cytoband', 'Alternative.symbols', 'Description'
UMAP
A typical exploration starts by constructing and plotting a UMAP model. In this notebook we use HoloViz for interactive plotting (hidden cell):
plot_pointscolours points with a numerical or categorical dimension.
The UMAP model is constructed using a correlation distance.
[92]:
def store_coordinates(df, projector, suffix="base"):
df.obs[f"x_{suffix}"] = projector.embedding_[:, 0]
df.obs[f"y_{suffix}"] = projector.embedding_[:, 1]
projector = UMAP(n_neighbors=30, metric="correlation", repulsion_strength=.01).fit(df.X)
lu.embed_graph(projector, repulsion_strengths=[.1, 1])
store_coordinates(df, projector, "base")
[93]:
selector = link_selections.instance(cross_filter_mode="overwrite")
points = plot_points(df.obs, ["relapsed"], suffix="base")
selector(points)
[93]:
The resulting graph contains one smaller and one larger community. By selecting the smaller community manually, we can figure out which genes make it differ from the larger community.
[ ]:
# Run after selecting the smaller community
selected_points = selector.filter(df.obs).index
df_sel = df[selected_points]
df_unsel = df[[n not in selected_points for n in df.obs_names]]
Like Lum et al. (2013), we perform a Kolmogorov-Smirnov test on each gene to detect which genes distinghuish the communities.
[ ]:
def compare_groups(df1, df2):
"""
Computes Kolmogorov-Smirnov test between the given populations for each gene.
Prints named genes from the top-10 most significant.
"""
Ds, ps = zip(*[kstest(df1.X[:, i], df2.X[:, i]) for i in range(df.shape[1])])
top_genes = 10
for idx in np.argpartition(ps, np.arange(top_genes))[:top_genes]:
name = df.var["HUGO.gene.symbol"].iloc[idx]
if type(name) is not str:
name = df.var["NCBI.gene.symbol"].iloc[idx]
if type(name) is str:
print(f"{name}:\t p={ps[idx]:.2e}, D={Ds[idx]:.2f}")
df.obs[name] = df.X[:, idx]
return Ds, ps
[ ]:
_ = compare_groups(df_unsel, df_sel)
FOXA1: p=7.08e-48, D=0.94
TBC1D9: p=1.11e-42, D=0.91
ESR1: p=1.11e-42, D=0.91
CA12: p=8.90e-42, D=0.90
PRR15: p=3.45e-40, D=0.89
AFF3: p=5.68e-40, D=0.89
GATA3: p=1.16e-38, D=0.88
AGR2: p=1.09e-37, D=0.87
In this list, the ESR1 gene might jump out to a domain expert, as it is generally understood to correlate with a patient’s prognosis. Plotting the relapse state and ESR1 values side-by-side reveals this relation. At least in the larger community more patients with a relapse (blue) lie towards the lower-ESR1-sides. Within the smaller community, the relapse state appears more balanced.
[ ]:
points = plot_points(df.obs, ["relapsed", "ESR1"], suffix="base")
points
Low ESR1 community
A follow-up question could investate which genes differ between relapse-free and with-relapse patients in the low ESR1 community. A Kolmogorov-Smirnov test provides this information:
[ ]:
# Run after selecting low-esr1 community
Ds, ps = compare_groups(
df[df_sel.obs_names[df_sel.obs.relapsed]],
df[df_sel.obs_names[~df_sel.obs.relapsed]],
)
RBP4: p=3.37e-04, D=0.54
ELOVL2: p=1.80e-03, D=0.49
CSTA: p=2.16e-03, D=0.48
CHAD: p=2.40e-03, D=0.48
ACP5: p=3.16e-03, D=0.47
GSTT1: p=5.27e-03, D=0.45
We can investigate the relation of these genes with the data by applying it as a lens, effectively emphasising their role in the distance metric. For example for CSTA:
[ ]:
lensed_csta = lu.apply_local_mask(
projector,
values=df.obs.CSTA,
n_neighbors=10,
repulsion_strength=.001,
)
lu.embed_graph(lensed_csta, repulsion_strengths=[.01, .1])
store_coordinates(df, lensed_csta, "CSTA")
The lens restructures the embedding such that both ESR1 and CSTA now vary along it smoothly, making it easier to interpret them.
[ ]:
plot_points(df.obs, ["relapsed", "ESR1", "CSTA"], suffix="CSTA").cols(3)
Looking at the distribution of patients with a relapses (blue) in the manifold, we can make several observations:
In the high-ESR1 community, relapsed patients lie mostly towards the lower ESR1-side. CSTA does not appear to influence too much, but there might be more relapses when both ESR1 and CSTA are low.
The low-ESR1 community appears to form a loop, indicating that it is not as connected to the large-ESR1 community through points with non-extreme CSTA values.
There appear to be more relapsed patients with low-ESR1 towards the low CSTA side.
Now we know to look for these genes, we can also visualise the data-point densities in an ESR1-CSTA scatterplot, confirming the patterns mentioned before:
[ ]:
def plot_distributions(obs, kdims):
relapsed = hv.Bivariate(obs[obs.relapsed], kdims).opts(cmap="Blues", bandwidth=0.3)
non_relapsed = hv.Bivariate(obs[~obs.relapsed], kdims).opts(cmap="Oranges", bandwidth=0.3)
return (non_relapsed * relapsed).opts(show_legend=False)
[ ]:
plot_distributions(df.obs, ["ESR1", "CSTA"])
Chemokine
Lum et al. mentioned several other genes that differentiate relapse state in the low ESR1 community. Here, we see how those genes behave on the UMAP manifold.
[ ]:
ncbi = df.var["NCBI.gene.symbol"]
hugo = df.var["HUGO.gene.symbol"]
ccl_genes = ["CCL3", "CCL13", "CXCL13", "PF4V1"]
gene_mask = (ncbi.apply(lambda x: x in ccl_genes)) | (
hugo.apply(lambda x: x in ccl_genes)
)
df.obs["Chemokine"] = np.nanmean(df[:, gene_mask].X, axis=1)
Their average significantly different in our selection:
[ ]:
D, p = kstest(
df.obs.Chemokine[df_low_esr1[~df_low_esr1.relapsed].index],
df.obs.Chemokine[df_low_esr1[df_low_esr1.relapsed].index],
)
print(f"Chemokine:\t p={p:.2f}, D={D:.2f}")
Chemokine: p=0.01, D=0.42
Let’s apply it as a lens as well:
[ ]:
lensed_chemokine = lu.apply_local_mask(
projector,
values=df.obs.Chemokine,
repulsion_strength=.001,
n_neighbors=10,
)
lu.embed_graph(projector, repulsion_strengths=[.01, .1])
store_coordinates(df, lensed_chemokine, "Chemokine")
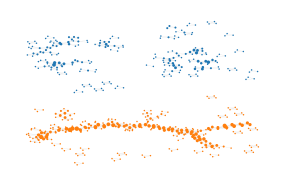
The resulting manifold looks like a Y, with one low Chemokine branch and two higher Chemokine branches. There do appear to be more relapsed patients with low-ESR1 and low Chemokine, but some relapsed patients also have low-ESR1 and high Chemokine values. That latter aspect might explain why these genes were not as significant in the Kolmogorov-Smirnov test.
[ ]:
selector = link_selections.instance(cross_filter_mode="overwrite")
points_5 = plot_points(df.obs, ["relapsed", "ESR1", "Chemokine"], suffix="Chemokine")
selector(points_5)
The density plot summarises these patterns:
Fewer survivors with low-ESR1 and low-Chemokine
Fewer survivors with mid-ESR1 and low-Chemokine
[ ]:
plot_distributions(selector.filter(df.obs), ["ESR1", "Chemokine"])
Conclusions
Combining Lenses with UMAP enables interactive exploration of the interactions between features and a dataset’s structure. When combined with domain knowledge or statistics to identify potentially interesting dimensions, applying a lens can help in gaining an understanding of the underlying patterns. In this example, we demonstrated using a lens that separates binary categories, enabling us to uncover differences in structure between the categories, and helping us compare feature-values between the categories visually. In addition, we used lenses on continuous dimensions to make them vary over the manifold smoothly, simplifying their interpretation.
Appendix:
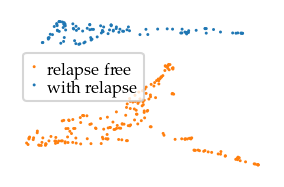
As a bonus, Lensed UMAP can reproduce the Y-shape in Lum et al.’s Mapper network when using eccentricity as lens. It is relevant to mention that UMAP does not need the eccentricity lens to interpret this data, as shown by the exploration above. Eccentricity does have an interesting effect, though, in that it visually separates the data set’s centre from its two more outside sides. In this case, the centre and sides mostly correspond to the elliptical shape of the UMAP embedding. From a domain knowledge perspective, eccentricity can be an interesting lens when one suspects that the data contains multiple ‘branches’, i.e. distinct but connected states different from a central core.
[ ]:
from sklearn.metrics import pairwise_distances
df.obs["eccentricity"] = pairwise_distances(df.X, metric="correlation").max(axis=1)
[13]:
lens_by_eccentricity = lu.apply_local_mask(
lu.apply_lens(
projector,
df.obs.relapsed.to_numpy(),
resolution=3,
skip_embedding=True,
),
values=df.obs.eccentricity.to_numpy(),
n_neighbors=5,
repulsion_strength=0.001,
)
lu.embed_graph(lens_by_eccentricity, repulsion_strengths=[0.01, 0.1])
tiled_embedding = lu.tile_components(
lens_by_eccentricity,
df.obs.relapsed.to_numpy(),
secondary_axis=df.obs.eccentricity.to_numpy(),
)
store_coordinates(df, tiled_embedding, "tiled")
[14]:
selector = link_selections.instance(cross_filter_mode="overwrite")
points_1 = plot_points(
df.obs, ["relapsed", "ESR1", "CSTA"], suffix="base"
)
points_6 = plot_points(
df.obs, ["relapsed", "ESR1", "CSTA"], suffix="tiled"
)
selector(points_1 + points_6).cols(3)
[14]:
[97]:
# Store generated dataframe!
df.write('./data/generated/nki.h5ad')
[6]:
sized_fig(base_frac, base_aspect)
plt.axis("off")
plt.subplots_adjust(0, 0, 1, 1)
plt.scatter(
df.obs.x_tiled[~df.obs.relapsed],
df.obs.y_tiled[~df.obs.relapsed],
2,
color="tab:orange",
label="relapse-free",
edgecolors="none",
)
plt.scatter(
df.obs.x_tiled[df.obs.relapsed],
df.obs.y_tiled[df.obs.relapsed],
2,
color="tab:blue",
label="with relapse",
zorder=-1,
edgecolors="none",
)
l = plt.legend(
loc="lower left",
bbox_to_anchor=(0, .4),
handletextpad=0.5,
handlelength=0.5,
labelspacing=0.1,
borderpad=0.4,
)
plt.setp(l.get_texts(), va="center")
plt.savefig("figures/nki_tiled_survival.pdf", pad_inches=0)
plt.show()
[79]:
sized_fig(base_frac, base_aspect)
plt.axis("off")
plt.subplots_adjust(0, 0, 1, 1)
plt.scatter(
df.obs.x_tiled,
df.obs.y_tiled,
2,
df.obs.ESR1,
cmap=cmap,
vmin=-1.5,
vmax=0.6,
edgecolors="none",
)
plt.savefig("figures/nki_tiled_esr1.pdf", pad_inches=0)
plt.show()
[80]:
fig = sized_fig(bar_frac, bar_aspect)
plt.axis("off")
plt.subplots_adjust(0, 0, 1, 1)
plt.scatter(
df.obs.x_tiled,
df.obs.y_tiled,
2,
df.obs.CSTA,
cmap=cmap,
vmin=-0.6,
vmax=0.6,
edgecolors="none",
)
cb = plt.colorbar(pad=0, fraction=0.18, shrink=0.89, aspect=15)
ticklabs = cb.ax.get_yticklabels()
cb.ax.set_yticklabels(ticklabs, ha="right")
cb.ax.tick_params(labelsize=8, pad=18)
plt.savefig("figures/nki_tiled_csta.pdf", pad_inches=0)
plt.show()
C:\Users\jelme\AppData\Local\Temp\ipykernel_15668\1313936354.py:16: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
cb.ax.set_yticklabels(ticklabs, ha="right")

Mapper
[106]:
from sklearn.metrics import pairwise_distances
from lib.mapper import compute_mapper_embedding
distances = pairwise_distances(df.X, metric="correlation")
eccentricity = distances.max(axis=0)
relapsed = df.obs.relapsed.to_numpy()
g, starts, ends = compute_mapper_embedding(
distances,
relapsed,
eccentricity,
# kind="balanced",
resolution=70,
overlap=2.01/3,
max_clusters_per_interval=4,
)
[107]:
import networkx as nx
from matplotlib import collections as mc
pos_attrs = nx.get_node_attributes(g, "pos")
size_attrs = nx.get_node_attributes(g, "size")
pts_attrs = nx.get_node_attributes(g, "points")
xs, ys = (np.asarray(x) for x in zip(*pos_attrs.values()))
source, target = [np.asarray(x) - 1 for x in zip(*g.edges)]
size_trace = [size_attrs[node] for node in pos_attrs.keys()]
norm = plt.Normalize(np.min(size_trace), np.max(size_trace))
size_trace = np.asarray([norm(s) * 4 + 0.5 for s in size_trace])
[108]:
esr1_values = df.obs.ESR1.to_numpy()
esr1_trace = np.asarray(
[esr1_values[pts_attrs[node]].mean() for node in pos_attrs.keys()]
)
sized_fig(base_frac, base_aspect)
plt.axis("off")
plt.subplots_adjust(0, 0, 1, 1)
plt.gca().add_collection(
mc.LineCollection(
np.column_stack((xs[source], ys[source], xs[target], ys[target])).reshape(
-1, 2, 2
),
linewidths=0.05,
colors="silver",
zorder=-1,
)
)
plt.scatter(
xs,
ys,
s=size_trace,
c=esr1_trace,
cmap=cmap,
edgecolors="none",
vmin=-0.6,
vmax=0.6,
)
plt.savefig("figures/nki_mapper_esr1.pdf", pad_inches=0)
plt.show()

[109]:
csta_values = df.obs.CSTA.to_numpy()
csta_trace = np.asarray(
[csta_values[pts_attrs[node]].mean() for node in pos_attrs.keys()]
)
sized_fig(bar_frac, bar_aspect)
plt.axis("off")
plt.subplots_adjust(0, 0, 1, 1)
plt.gca().add_collection(
mc.LineCollection(
np.column_stack((xs[source], ys[source], xs[target], ys[target])).reshape(
-1, 2, 2
),
linewidths=0.05,
colors="silver",
zorder=-1,
)
)
plt.scatter(
xs,
ys,
s=size_trace,
c=csta_trace,
cmap=cmap,
edgecolors="none",
vmin=-0.6,
vmax=0.6,
)
cb = plt.colorbar(pad=0, fraction=0.18, shrink=0.89, aspect=15)
ticklabs = cb.ax.get_yticklabels()
cb.ax.set_yticklabels(ticklabs, ha="right")
cb.ax.tick_params(labelsize=8, pad=18)
plt.savefig("figures/nki_mapper_csta.pdf", pad_inches=0)
plt.show()
C:\Users\jelme\AppData\Local\Temp\ipykernel_15668\2672881227.py:31: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
cb.ax.set_yticklabels(ticklabs, ha="right")

[ ]:
relapse_trace = np.asarray(
[relapsed[pts_attrs[node]].any() for node in pos_attrs.keys()]
)
sized_fig(base_frac, base_aspect)
plt.axis("off")
plt.subplots_adjust(0, 0, 1, 1)
plt.gca().add_collection(
mc.LineCollection(
np.column_stack((xs[source], ys[source], xs[target], ys[target])).reshape(
-1, 2, 2
),
linewidths=0.05,
colors="silver",
zorder=-1,
)
)
plt.scatter(
xs[~relapse_trace],
ys[~relapse_trace],
s=size_trace[~relapse_trace],
color="tab:orange",
label="relapse-free",
edgecolors="none",
)
plt.scatter(
xs[relapse_trace],
ys[relapse_trace],
s=size_trace[relapse_trace],
color="tab:blue",
label="with relapse",
edgecolors="none",
)
plt.savefig("figures/nki_mapper_survival.pdf", pad_inches=0)
plt.show()
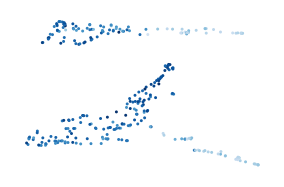
Most points are (over) represented four to five times!
[112]:
counts = np.zeros(df.shape[0])
for pts in pts_attrs.values():
counts[pts] += 1
for cnt in range(1, 6):
pct = (counts == cnt).sum() / counts.shape[0] * 100
print(f"{pct:.2f}% of points are in {cnt} clusters")
pct = (counts >= 3).sum() / counts.shape[0] * 100
print(f"{pct:.2f}% of points are in 3 or more clusters")
1.99% of points are in 1 clusters
2.65% of points are in 2 clusters
46.03% of points are in 3 clusters
49.01% of points are in 4 clusters
0.00% of points are in 5 clusters
95.03% of points are in 3 or more clusters
[113]:
g.number_of_nodes(), df.shape[0]
[113]:
(504, 302)