4. Document-oriented databases
4.1. Introduction
In contrast to relational databases (RDBMS) which define their columns at the table level, document-oriented databases (also called document stores) define their fields at the document level. You can imagine that a single row in a RDBMS table corresponds to a single document where the keys in the document correspond to the column names in the RDBMS. Let’s look at an example table in a RDBMS containing information about buildings:
| id | name | address | city | type | nr_rooms | primary_or_secondary |
|---|---|---|---|---|---|---|
1 |
building1 |
street1 |
city1 |
hotel |
15 |
|
2 |
building2 |
street2 |
city2 |
school |
primary |
|
3 |
building3 |
street3 |
city3 |
hotel |
52 |
|
4 |
building4 |
street4 |
city4 |
church |
||
5 |
building5 |
street5 |
city5 |
house |
||
… |
… |
… |
… |
… |
… |
This is a far from ideal way for storing this data because many cells will remain empty based on the type of building their rows represent: the primary_or_secondary column will be empty for every single building except for schools. Also: what if we want to add a new row for a type of building that we don’t have yet? For example: a shop for which we also need to store the weekly closing day. To be able to do that, we’d need to first alter the whole table by adding a new column.
In document-oriented databases, these keys are however stored with the documents themselves. A typical way to represent this is as in JSON format, and can be represented as such:
[
{ id: 1, name: "building1", address: "street1", city: "city1",
type: "hotel", nr_rooms: 15 },
{ id: 2, name: "building2", address: "street2", city: "city2",
type: "school", primary_or_secondary: "primary" },
{ id: 3, name: "building3", address: "street3", city: "city3",
type: "hotel", nr_rooms: 52 },
{ id: 4, name: "building4", address: "street4", city: "city4",
type: "church" },
{ id: 5, name: "building5", address: "street5", city: "city5",
type: "house" },
{ id: 6, name: "building6", address: "street6", city: "city6",
type: "shop", closing_day: "Monday" }
]Notice that in the document for a house (id of 5), there is no mention of primary_of_secondary because it is not relevant as it is for a hotel.
4.2. Concepts
4.2.1. Naming things: collections and documents
The way that things are named in document stores is a bit different than in RDBMS, but in general a collection in a document store corresponds to a table in a RDBMS, and a document corresponds to a row.
As a comparison, consider the following examples of a relational database vs a document database for storing blog data.
Blog information stored in RDBMS
Table posts
| id | author_id | date | title | text |
|---|---|---|---|---|
1 |
4 |
4-5-2020 |
COVID-19 lockdown |
It seems that… |
4 |
4 |
5-5-2020 |
Schools closed |
As the number of COVID-19 cases is growing … |
… |
… |
… |
… |
… |
Table authors
| id | name | |
|---|---|---|
1 |
Santa Claus |
|
2 |
Easter Bunny |
|
… |
… |
… |
Each table has rows.
Blog information stored in document database
Collection posts
{ title: "COVID-19 lockdown", date: "4-5-2020",
author: { name: "Geert Molenberghs", email: "geert@gmail.com" },
text: "It seems that..." },
{ title: "Schools closed", date: "5-5-2020",
author: { name: "Geert Molenberghs", email: "geert@gmail.com" },
text: "As the number of COVID-19 cases is growing, ..."}This is one collection with two documents.
4.2.2. Documents are schemaless
As mentioned above, one of the important differences between RDBMS and document databases, is that documents are schemaless. Actually, we should say that they have a flexible schema. What does this mean? Consider the case where we are collecting data on bird migrations (as for example https://www.belgianbirdalerts.be/). In an RDMBS, we could put this information in a sightings table.
sightings
| id | species_la | species_en | date_time | municipality |
|---|---|---|---|---|
1 |
Emberiza pusilla |
Little Bunting |
30-09-2020 15:37 |
Zeebrugge (BE) |
2 |
Sylvia nisoria |
Barred Warbler |
2020-10-01 13:45 |
Zeebrugge (BE) |
… |
… |
… |
… |
… |
What if we want to store the Dutch name as well? Then we’d need to alter the table schema to have a new column to hold that information: ALTER TABLE sightings ADD species_du TEXT;. After adding this column and updating the value in that particular column, we get the following:
sightings
| id | species_la | species_en | species_du | date_time | municipality |
|---|---|---|---|---|---|
1 |
Emberiza pusilla |
Little Bunting |
Dwerggors |
30-09-2020 15:37 |
Zeebrugge (BE) |
2 |
Sylvia nisoria |
Barred Warbler |
Sperwergrasmus |
2020-10-01 13:45 |
Zeebrugge (BE) |
So far so good: this table still looks clean. Now imagine that we want to improve the reporting, and actually include the longitude and latitude instead of just the municipality. Also, we want to split up the date from the time. To do this, we have to alter the schema of the sightings table to include these new columns. Only after we changed this schema, we can input data using the new information:
sightings
| id | species_la | species_en | species_du | date_time | municipality | date | time | lat | long |
|---|---|---|---|---|---|---|---|---|---|
1 |
Emberiza pusilla |
Little Bunting |
Dwerggors |
30-09-2020 15:37 |
Zeebrugge (BE) |
||||
2 |
Sylvia nisoria |
Barred Warbler |
Sperwergrasmus |
2020-10-01 13:45 |
Zeebrugge (BE) |
||||
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
56 |
Elanus caeruleus |
Black-winged Kite |
Grijze Wouw |
2020-10-02 |
15:15 |
50.96577 |
3.92744 |
||
57 |
Ficedula parva |
Red-breasted Flycatcher |
Kleine Vliegenvanger |
2020-10-04 |
10:34 |
51.33501 |
3.23154 |
||
58 |
Phalaropus lobatus |
Red-necked Phalarope |
Grauwe Franjepoot |
2020-10-04 |
10:48 |
51.14660 |
2.73363 |
||
59 |
Locustella certhiola |
Pallas’s Grasshopper Warbler |
Siberische Sprinkhaanzanger |
2020-10-04 |
11:53 |
51.33950 |
3.22775 |
||
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
Executing an ALTER TABLE on a relational database is a huge step. Having a well-defined schema is core to a RDBMS, so changing it should not be done lightly.
In contrast, nothing would need to be done to store this new information if we had been using a document-database. Consider our initial data:
{ id: 1,
species_la: "Emberiza pusilla", species_en: "Little Bunting",
date_time: "30-09-2020 15:37", municipality: "Zeebrugge, BE"},
{ id: 2,
species_la: "Sylvia nisoria", species_en: "Barred Warbler",
date_time: "2020-10-01 13:45", municipality: "Zeebrugge, BE"},
...If we want to change from reporting municipality to latitude and longitude, we just add those instead on new documents:
{ id: 1,
species_la: "Emberiza pusilla", species_en: "Little Bunting",
date_time: "30-09-2020 15:37", municipality: "Zeebrugge, BE" },
{ id: 2,
species_la: "Sylvia nisoria", species_en: "Barred Warbler",
date_time: "2020-10-01 13:45", municipality: "Zeebrugge, BE" },
...
{ id: 56,
species_la: "Elanus caeruleus", species_en: "Black-winged Kite", species_du: "Grijze Wouw",
date: "2020-10-02", time: "15:15",
lat: 50.96577, long: 3.92744 },
{ id: 57,
species_la: "Ficedula parva", species_en: "Red-breasted Flycatcher", species_du: "Kleine Vliegenvanger",
date: "2020-10-04", time: "10:34",
lat: 51.33501, long: 3.23154 },
...Explicit vs implicit schema
|
Important
|
Even though a document database does not enforce a strict schema, there is still an implicit schema: it’s the combination of keys and possible values that can be present in a document. The application (or you) need to know that the English species name is stored with the key species_en. It should not be a mix of species_en in some cases, species_english in others, or english_name or english_species_name, etc. That would make it impossible to for example get a list of all species that were sighted.
|
4.2.3. Embedding vs referencing
When modelling data in a relational database, we typically try to create a normalised database schema. In such schema, different concepts are stored in different tables, and information is linked by referencing rows in different tables.
Consider the example of a blog. This information concerns different concepts: the blog itself, posts on that blog, authors, comments, and tags. This can be modelled like this in a relational database:
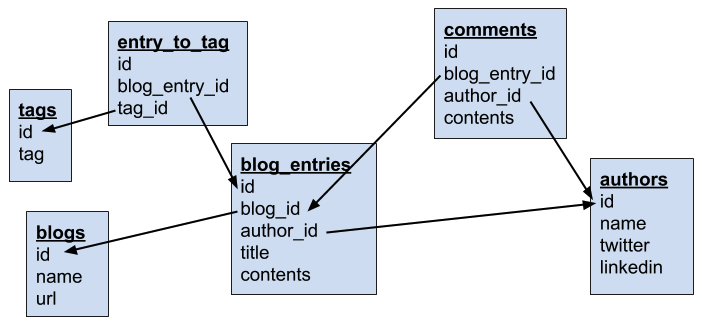
Each concept is stored in a separate table. To get all comments on posts written by John Doe, we can do this (we won’t go into actual schemas here):
SELECT c.date, c.comment
FROM authors a, blog_entries b, comments c
WHERE a.id = b.author_id
AND b.id = c.entry_id
AND a.name = "John Doe";In document databases, we have to find a balance between embedding and referencing.
On the one extreme end, we can follow the same approach as in relational databases, and create a separate collection for each concept. So there would be a collection for blogs, one for blog_entries, for authors, for comments and tags. At the other extreme end, we can embed some of this information. For example, a single blog entry can have the author name and email, the comments and tags inside it.
A referencing-heavy approach:
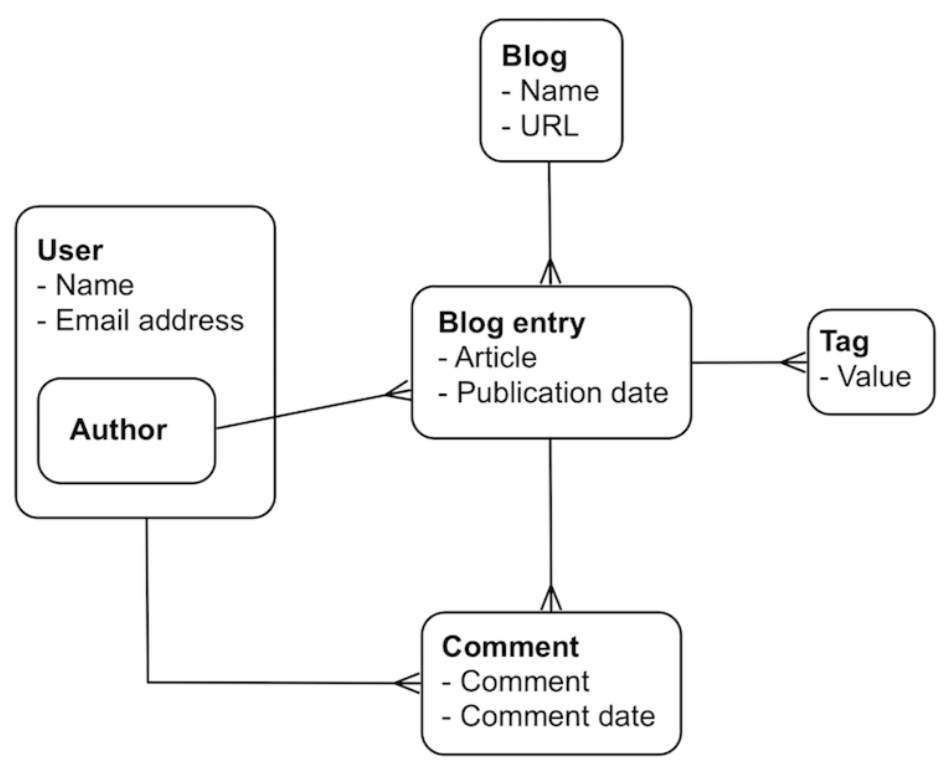
A mixed reference-embed approach:
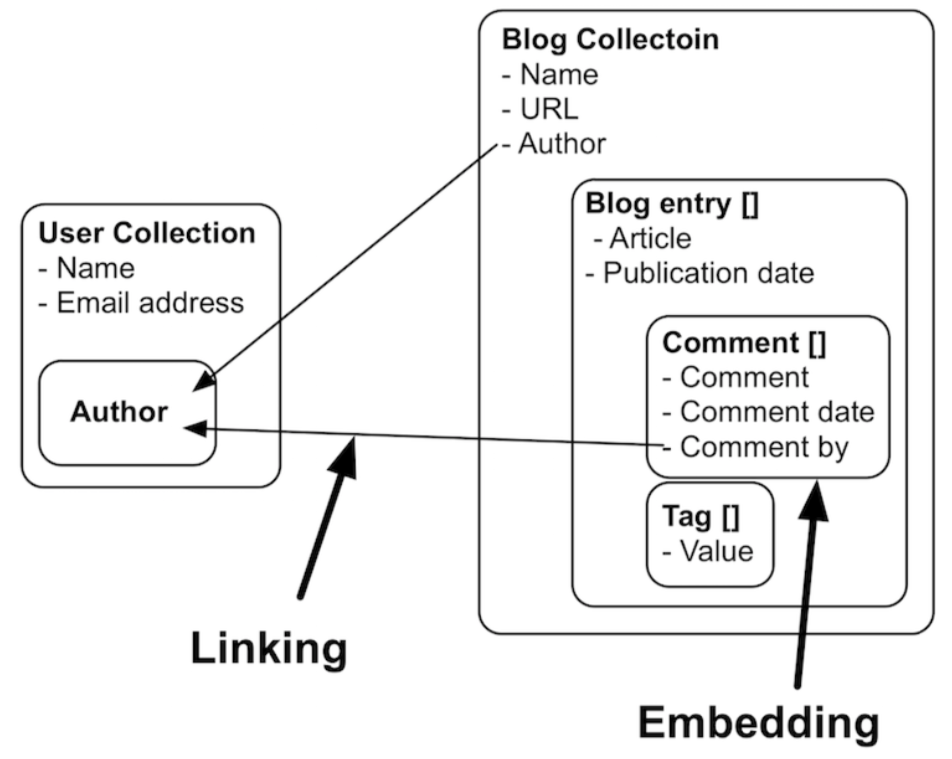
On cross-collection queries
In many document database-implementations (e.g. mongodb) it is not possible to query across collections, which can make using referenced data much more difficult. A query in mongodb, for example, will look like this (don’t worry about the exact syntax; it should be clear what this tries to do):
db.comments.find({author_id: 5})This will return all comments written by the author with ID 5. To get all comments on posts written by author John Doe we would have to do the following if we’d use a full referencing approach:
-
Find out what the ID is of "John Doe":
db.authors.find({name: "John Doe"}). Let’s say that this returns the document{id: 8, name: "John Doe", twitter: "JohnDoe18272"}. -
Find all blog entries written by him:
db.blog_entries.find({author_id: 8}). Let’s say that this returns the following list of blog posts:
[{id: 26, author_id: 8, date: 2020-08-17,
title: "A nice vacation", text: "..."},
{id: 507, author_id: 8, date: 2020-08-23,
title: "How I broke my leg", text: "..."}]-
Find all the comments that are linked to one of these posts:
db.comments.find({blog_entry_id: [26,507]}).
As you can see, we need 3 different queries to get that information, which means that the database is accessed 3 times. In contrast, with embedding all the relevant information can be extracted with just a single query. Let’s say that information is stored like this:
[{id: 26, author: { name: "John Doe", twitter: "JohnDoe18272" },
date: 2020-08-17,
title: "A nice vacation", text: "...",
comments: [ {date: ..., author: {...},
{date: ..., author: {...}}
]},
{id: 507, author: { name: "John Doe", twitter: "JohnDoe18272" },
date: 2020-08-23,
title: "How I broke my leg", text: "...",
comments: [ {date: ..., author: {...},
{date: ..., author: {...}}
]},
{id: 507, author: { name: "Superman", twitter: "Clark" },
date: 2020-09-03,
title: "A view from the sky", text: "...",
comments: [ {date: ..., author: {...},
{date: ..., author: {...}}
]},
...
]Now to get all comments on posts written by John Doe, you only need a single query: db.blog_entries.find({name:"John Doe"}) and therefore a single trip to the database.
BTW: Notice how the author information is duplicated in this example. Again: find a balance between linking and embedding…
Document-databases are often aggregation-oriented
This possibility for embedding makes that document databases have an aspect of aggregation-orientation to them. Whereas in RDBMS new information is pulled apart and stored in different tables, in a document database all this information can be stored together.
For example, consider a system that needs to store genotyping information. With genotyping, part of an person’s DNA is read and an A, C, T or G is assigned to particular positions in the genome (single nucleotide polymorphisms or SNPs). In a relational database model, it looks like this:
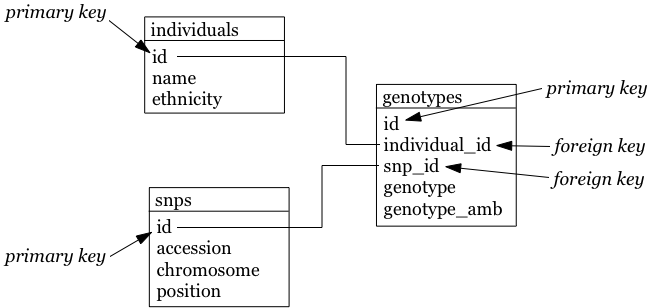
individuals table:
| id | name | ethnicity |
|---|---|---|
1 |
individual_A |
caucasian |
2 |
individual_B |
caucasian |
snps table:
| id | name | chromosome | position |
|---|---|---|---|
1 |
rs12345 |
1 |
12345 |
2 |
rs98765 |
1 |
98765 |
3 |
rs28465 |
5 |
23456 |
genotypes table:
| id | snp_id | individual_id | genotype | ambiguity_code |
|---|---|---|---|---|
1 |
1 |
1 |
A/A |
A |
2 |
2 |
1 |
A/G |
R |
3 |
3 |
1 |
G/T |
K |
4 |
1 |
2 |
A/C |
M |
5 |
2 |
2 |
G/G |
G |
6 |
3 |
2 |
G/G |
G |
To get all information for individual_A we need to write a join that gets information from different tables:
SELECT i.name, i.ethnicity, s.name, s.chromosome, s.position, g.genotype
FROM individuals i, snps s, genotypes g
WHERE i.id = g.individual_id
AND s.id = g.snp_id
AND i.name = 'individual_A';In a document database, we can store this by individual, for example in a genotype_documents collection:
{ id: 1, name: "individual_A", ethnicity: "caucasian",
genotypes: [ { name: "rs12345", chromosome: 1, position: 12345, genotype: "A/A" },
{ name: "rs9876", chromosome: 1, position: 9876, genotype: "A/G" },
{ name: "rs28465", chromosome: 5, position: 23456, genotype: "G/T" }]}
{ id: 1, name: "individual_B", ethnicity: "caucasian",
genotypes: [ { name: "rs12345", chromosome: 1, position: 12345, genotype: "A/C" },
{ name: "rs9876", chromosome: 1, position: 9876, genotype: "G/G" },
{ name: "rs28465", chromosome: 5, position: 23456, genotype: "G/G" }]}In this case, it is much easier to get all information for individual_A. Such query could simply be: db.genotype_documents({name: 'individual_A'}). This is because all data is aggregated by individual.
But what if we want all genotypes that were recorded for SNP rs9876 across all individuals? In SQL, the query would be very similar to the one for individual_A:
SELECT i.name, i.ethnicity, s.name, s.chromosome, s.position, g.genotype
FROM individuals i, snps s, genotypes g
WHERE i.id = g.individual_id
AND s.id = g.snp_id
AND s.name = 'rs9876';We do however loose the advantage of the individual-centric model completely with our document database: a query (although it might look simple) will have to extract a little piece of information from every single document in the database which is extremely costly. If we knew we were going to ask this question, it’d have been better to model the data like this:
{ id: 1, name: "rs12345", chromosome: 1, position: 12345,
genotypes: [ { name: "individual_A", genotype: "A/A"},
{ name: "individual_B", genotype: "A/C"} ] },
{ id: 1, name: "rs9876", chromosome: 1, position: 9876,
genotypes: [ { name: "individual_A", genotype: "A/G"},
{ name: "individual_B", genotype: "G/G"} ] },
{ id: 1, name: "rs28465", chromosome: 1, position: 23456,
genotypes: [ { name: "individual_A", genotype: "G/T"},
{ name: "individual_B", genotype: "G/G"} ] }So do you model your data by individual or by SNP? That depends…
-
If you know beforehand that you’ll be querying by individual and not by SNP, use the first version.
-
If by SNP, use the latter.
-
You could model in a similar way as the relational database with separate collections for
individuals,snpsandgenotypes. In other words: using linking rather than embedding. -
You could do both, but not as the master dataset. In this case, you have a master dataset from which you recalculate these two different versions of the same data on a regular basis (daily, weekly, …, depending on the update frequency). This latter approach fits in the Lambda Architecture that we’ll talk about later.
4.2.4. Homogeneous vs heterogeneous collections
Now should every collection be about one specific thing, or not? Above, we asked the question if every concept should be separate in their own collection or if we want to embed information, or if we want to merge different objects into a single document. Still, the documents within a collection would still be the same. Whether or not we embed the author information in the blog entries, the blog_entries collection is still about blog entries.
This is however not mandatory, and nothing keeps you from putting all kinds of documents all together in the same collection. Consider the example of a large multi-day conference with many speakers, who hold different talks in different rooms.
Homogeneous design
In a homogeneous design, we put our speakers, rooms and talks in different collections:
speakers
[ { id: 1, name: "John Doe", twitter: "JohnDoe18272" },
{ id: 2, name: "Superman", twitter: "Clark" },
... ]rooms
[ { id: 1, name: "1st floor left", floor: 1, capacity: 80},
{ id: 2, name: "lecture hall 2", floor: 1, capacity: 200},
... ]talks
[ { id: 1, speaker_id: 1, room_id: 4, time: "10am", title: "Fun with deep learning" },
{ id: 2, speaker_id: 1, room_id: 2, time: "2pm", title: "How I solved world hunger"},
... ]Heterogeneous design
The above is a perfectly valid approach for storing this type of data. In some cases, however, you might anticipate that you often want to have information from different types. Let’s say that you expect to want to find everything that is related to room 4. In the above setup, you’d have to run 3 different queries; one for each collection.
Another approach is to actually put all that information together. To make sure that we can still query specific types of information (e.g. just the speakers), let’s add an additional key type (can be anything). Let’s call the collection agenda:
[ { id: 1, type: "speaker", speaker_id: 1, name: "John Doe", twitter: "JohnDoe18272" },
{ id: 2, type: "speaker", speaker_id: 2, name: "Superman", twitter: "Clark" },
{ id: 3, type: "room", room_id: 1, name: "1st floor left", floor: 1, capacity: 80},
{ id: 4, type: "room", room_id: 2, name: "lecture hall 2", floor: 1, capacity: 200},
{ id: 5, type: "talk", speaker_id: 1, room_id: 4, time: "10am", title: "Fun with deep learning" },
{ id: 6, type: "talk", speaker_id: 1, room_id: 2, time: "2pm", title: "How I solved world hunger"},
... ]Now to get all information available for room with ID 2, we just get db.agenda.find({room_id: 2}) which will return speakers, rooms and talks:
[ { id: 4, type: "room", room_id: 2, name: "lecture hall 2", floor: 1, capacity: 200},
{ id: 6, type: "talk", speaker_id: 1, room_id: 2, time: "2pm", title: "How I solved world hunger"},
... ]To just get the talks that are given in that room (so not the room itself) we just add the additional constraint on type: db.agenda.find({room_id: 2, type: "talk"}).
Source of some of this information: Ryan Crawcour & David Makogon
4.3. Data modeling
4.3.1. Think about how you will use the data
The starting point for modelling your data is different between an RDBMS and a document database. With an RDBMS, you typically start from the data; with a document database, you typically start from the application.
Think about how we will use the data, and how they will be accessed. Consider, for example, a movie dataset with actors and movies. For each actor we have their name , date of birth and the movies they acted in. For each movie, we have the title, release year, and tagline. There are different ways in which we can model this data in a document database, depending on what the intended use will be. So what do you want to do with this data? Do you want to answer questions about the actors? Or about the movies?
So the two obvious approaches are movie-centric
{ movie: "As Good As It Gets",
released: 1997,
tagline: "A comedy from the heart that goes for the throat",
actors: [{ name: "Jack Nicholson", born: 1937 },
{ name: "Cuba Gooding Jr.", born: 1968 },
{ name: "Helen Hunt", born: 1963 },
{ name: "Greg Kinnear", born: 1963 }]},
{ movie: "A Few Good Men",
released: 1992,
tagline: "In the heart of the nation's capital, ...",
actors: [{ name: "Jack Nicholson", born: 1937 },
{ name: "Demi Moore", born: 1962 },
{ name: "Cuba Gooding Jr.", born: 1968 },
{ name: "Tom Cruise", born: 1962 }]}or actor-centric:
{ name: "Jack Nicholson", born: 1937,
movies: [{ name: "As Good As It Gets", released: 1997,
tagline: "A comedy from the heart that goes for the throat" },
{ name: "A Few Good Men", released: 1992,
tagline: "In the heart of the nation's capital, ..."}]},
{ name: "Cuba Gooding Jr.", born: 1968,
movies: [{ name: "As Good As It Gets", released: 1997,
tagline: "A comedy from the heart that goes for the throat" },
{ name: "A Few Good Men", released: 1992,
tagline: "In the heart of the nation's capital, ..."},
{ name: "What Dreams May Come", released: 1998,
tagline: "After life there is more. The end is just the beginning."}]},
{ name: "Tom Cruise", born: 1962,
movies: [{ name: "A Few Good Men", released: 1992,
tagline: "In the heart of the nation's capital, ..."},
{ name: "Jerry Maguire", released: 2000,
tagline: "The rest of his life begins now."}]}Searching using an actor-centric query in a movie-centric database will be very inefficient. If we want to know in how movies Jack Nicholson played using the first approach above, we have to go through all documents and check which has him mentioned in the list of actors. Using the second approach above, we only have to get the single document about him and we have all the information.
Another option is to use links or references. The actors collection could then be:
{ _key: "JNich", name: "Jack Nicholson", born: 1937,
movies ["AGAIG","AFGM"]}
{ _key: "TCrui", name: "Tom Cruise", born: 1962,
movies: ["AFGM","JM"]}and the movies collection:
{ _key: "AGAIG", title: "As Good As It Gets", release: 1997,
tagline: "A comedy from the heart that goes for the throat",
actors: ["JNich", "CGood", "HHunt", "GKinn"]},
{ _key: "AFGM", title: "A Few Good Men", release: 1992,
tagline: "In the heart of the nation's capital, ...",
actors: ["JNich", "DMoor", "CGood", "TCrui"]}In this case the movies or actors key in the document refers to the _key in the other collection.
The above are just some of the ways to model your data. Below, we’ll go deeper into how you can approach different types of relationships between documents.
4.3.2. Relationships between documents
So when do you embed, and when do you reference?
1-to-1 relationships
If you have a 1-to-1 relationship, just add a key-value pair in the document. For example, an individual having only a single twitter account would just have that account added as a key-value pair:
{ name: "Elon Musk",
born: 1971,
twitter: "@elonmusk" }
1-to-few relationships
If you have a 1-to-few relationship (i.e. a 1-to-many where the "many" is not "too many"), it’s easiest to embed the information in a list. For example for Elon Musk’s citizenships:
{ name: "Elon Musk",
born: 1971,
twitter: "@elonmusk",
citizenships: [
{ country: "South Africa", since: 1971 },
{ country: "Canada", since: 1971 },
{ country: "USA", since: 2002 }
]}1-to-many relationships
The above works as long as you don’t have thousands of elements in such an array. Consider a car; which apparently on average consists of 30,000 parts. We don’t want to store all information for each parts in a huge array. Because each element in that array will have information like it’s name, number, cost, provider, how many we need, etc. In this case, we can choose to use references instead of embedding.

cars collection:
{ _key: "car1",
name: "left-handed Tesla Model S",
manufacturer: "Tesla",
catalog_number: 12345,
parts: ["p1","p3","p17",...]}parts collection:
{ _key: "p1",
partno: "123-ABC-987",
name: "nr 4 bolt",
qty: 105,
cost: 0.54 },
{ _key: "p3",
partno: "826-CKW-732",
name: "nr 6 grommet",
qty: 68,
cost: 0.52 },
...1-to-immense relationships
This works fine, until you’re in the situation where you have a huge number of elements. You should never use an array that is basically unbounded, so that grows really big. For example, think about sensors that store information every second, or server logs.
{ id: "server_17",
location: "server room 2",
messages: [
{ date: "Oct 14 07:50:29",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:35",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:37",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:42",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39",
message: "Failed to bootstrap path /System/Library, error = 2: No such file or directory" },
{ date: "Oct 14 07:50:43",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
...
]}A better approach here is to use a reverse reference, where the host is referenced. That brings the log messages themselves first-grade documents.
servers collection:
{ id: "server_17",
location: "server room 2" }logs collections:
{ date: "Oct 14 07:50:29", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:35", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:37", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:42", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39", host: "server_17",
message: "Failed to bootstrap path /System/Library, error = 2: No such file or directory" },
{ date: "Oct 14 07:50:43", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
...many-to-many relationships
A possible approach to follow with many-to-many relationships is to create reciprocal references: the links are present twice. For example, authors and books: a single author can write multiple books; a single book can have multiple authors.
books collection:
{ id: "go", ISBN13: "9780060853983",
title: "Good Omens: The Nice and Accurate Prophecies of Agnes Nutter, Witch",
authors: ["tprat","ngaim"] },
{ id: "gp", ISBN13: "9780060502935",
title: "Going Postal (Discworld #33)",
authors: ["tprat"] },
{ id: "sg", ISBN13: "9780552152976",
title: "Small Gods (Discworld #13)",
authors: ["tprat"] },
{ id: "tsa", ISBN13: "9780060842352",
title: "The Stupidest Angel: A Heartwarming Tale of Christmas Terror",
authors: ["cmoor"] }authors collection:
{ id: "tprat", name: "Terry Pratchett", books: ["go","gp","sg"] },
{ id: "ngaim", name: "Neil Gaiman", books: ["go"] },
{ id: "cmoor", name: "Christopher Moore", books: ["tsa"] }|
Caution
|
This approach can quickly lead to inconsistencies if not handled well. What if an author has written a certain book, but that book does not mention that author? |
Another option is to use a collection specific for the links, similar to a linking table in an RDBMS:
books collection:
{ id: "go", ISBN13: "9780060853983",
title: "Good Omens: The Nice and Accurate Prophecies of Agnes Nutter, Witch" },
{ id: "gp", ISBN13: "9780060502935",
title: "Going Postal (Discworld #33)" },
{ id: "sg", ISBN13: "9780552152976",
title: "Small Gods (Discworld #13)" },
{ id: "tsa", ISBN13: "9780060842352",
title: "The Stupidest Angel: A Heartwarming Tale of Christmas Terror" }authors collection:
{ id: "tprat", name: "Terry Pratchett" },
{ id: "ngaim", name: "Neil Gaiman" },
{ id: "cmoor", name: "Christopher Moore" }authorships collection:
{ author: "tprat", book: "go" },
{ author: "tprat", book: "gp" },
{ author: "tprat", book: "sg" },
{ author: "ngaim", book: "go" },
{ author: "cmoor", book: "tsa" },Other considerations
Use embedding for…
-
things that are queried together should be stored together. In the blog example, it will be uncommon that you’d want to have a list of comments without them being linked to the blog entry itself. In this case, the comments can be embedded in the blog entry.
-
things with similar volatility (i.e. their rate of change is similar). For example, an
authorcan have several social IDs on Facebook, Linkedin, Twitter, etc. These things will not change a lot so it makes sense to store them inside theauthordocument, rather than having a separate collectionsocial_networksand link the information between documents. -
set of values or subdocuments that are bounded (1-to-few relationship). For example, the number of tags for a blog entry will not be immense, and be static so we can embed that.
Data embedding has several advantages:
-
The embedded objects are returned in the same query as the parent object, meaning that only 1 trip to the database is necessary. In the example above, if you’d query for a blog entry, you get the comments and tags with it for free.
-
Objects in the same collection are generally stored sequentially on disk, leading to fast retrieval.
-
If the document model matches your domain, it is much easier to understand than a normalised relational database.
Use referencing for…
-
1-to-many relationships. For example, a single author can write multiple blog posts. We don’t want to copy the author’s name, email, social network usernames, picture, etc into every single blog entry.
-
many-to-many relationships. What is a single author has written multiple blog posts, and blog posts can be co-written by many authors?
-
related data that changes with different volatility. Let’s say that we also record "likes" and "shares" for blog posts. That information is much less important and changes much quicker than the blog entry itself. Instead of constantly updating the blog document, it’s safer to keep this outside.
Typically you would combine embedding and referencing.
4.3.3. Conclusion
Data modelling in document-oriented databases is not straightforward and there is no single solution. It all depends on what you want to do. This is different from data modelling in RDBMS where you can work towards a normalised database schema.
4.4. Data modeling patterns
According to Wikipedia, "a […] design pattern is a general, reusable solution to a commonly occurring problem". This is also true for designing the data model (of data schema) in document databases. Below, we will go over some of these design patterns. A more complete list and explanation is available on e.g. the MongoDB blog. Many of the examples below also come from that source.
4.4.1. Attribute pattern
In the attribute pattern, we group similar fields (i.e. with the same value type) into a single array. Consider for example the following document on the movie "Star Wars":
{ title: "Star Wars",
new_title: "Star Wars: Episode IV - A New Hope",
director: "George Lucas",
release_US: "1977-05-20",
release_France: "1977-10-19",
release_Italy: "1977-10-20",
...
}To make quick searches on the release date we’d have to put an index on every single key that starts with release_. Another approach is to put these together in a separate attribute:
{ title: "Star Wars",
new_title: "Star Wars: Episode IV - A New Hope",
director: "George Lucas",
releases: [
{ country: "US", date: "1977-05-20" },
{ country: "France", date: "1977-10-19" },
{ country: "Italy", date: "1977-10-20" },
...
]
}In this case we only have to make a combined index on releases.country and releases.date.
4.4.2. Bucket pattern
Do you always want to store each datapoint in a separate document? You don’t have to. A good example is time-series data, e.g. from sensors. If those sensors return a value every second, you will end up with a lot of documents. Especially if you’re not necessarily interested in that resolution it makes sense to bucket the data.
For example, you could store data from a temperature sensor like this:
{ sensor_id: 1,
datetime: "2020-10-12 10:10:58",
value: 27.3 },
{ sensor_id: 1,
datetime: "2020-10-12 10:10:59",
value: 27.3 },
{ sensor_id: 1,
datetime: "2020-10-12 10:11:00",
value: 27.4 },
{ sensor_id: 1,
datetime: "2020-10-12 10:11:01",
value: 27.4 },
...But obviously we’re not really interested in the per-second readings. A more proper time period could be e.g. each 5 minutes. Your document would - using the bucket pattern - then look like this:
{ sensor_id: 1,
start: "2020-10-12 10:10:00",
end: "2020-10-12 10:15:00",
readings: [
{ timestamp: "2020-10-12 10:10:01", value: 27.3 },
{ timestamp: "2020-10-12 10:10:02", value: 27.3 },
{ timestamp: "2020-10-12 10:10:03", value: 27.3 },
...
{ timestamp: "2020-10-12 10:14:59", value: 27.4 },
]
}This has several advantages:
-
it fits more with the time granularity that we are thinking in
-
it will be easy to compute aggregations in this granularity
-
if we see that we don’t need the high-resolution data after a while, we can safely delete the
readingspart if we need to (e.g. to safe on storage space)
4.4.3. Computed pattern
Using buckets is actually a great segue into the computed pattern.
It is not unusual that you end up extracting information from a database and immediately make simple or complex calculations. At that point you can make the decision to store the pre-computed values in the database as well. Technically you’re duplicating data (the original fields plus a derived field), but it might speed up your application a lot.
In the bucket pattern example above, we want to always look at the average temperature in those 5-minute intervals. We can calculate that every time we fetch the data from the database, but we can actually pre-calculate it as well and store that result in the document itself.
{ sensor_id: 1,
start: "2020-10-12 10:10:00",
end: "2020-10-12 10:15:00",
readings: [
{ timestamp: "2020-10-12 10:10:01", value: 27.3 },
{ timestamp: "2020-10-12 10:10:02", value: 27.3 },
{ timestamp: "2020-10-12 10:10:03", value: 27.3 },
...
{ timestamp: "2020-10-12 10:14:59", value: 27.4 },
]
avg_reading: 27.326
}4.4.4. Extended reference
We use the extended reference when we need many joins to bring together frequently accessed data. For example, consider information on customers and orders. Because this is a many-to-many relationship, we would use a referencing approach, and store a particular customer and one of their orders like this (yet another example from the MongoDB website):
In the customers collection:
{ _id: "cust_123",
name: "Katrina Pope",
address: "123 Main Str",
city: "Somewhere",
country: "Someplace",
dateofbirth: "1992-11-03",
social_networks: [
{ twitter: "@me123" }]
}In the orders collection:
{ _id: "order_1827",
date: "2019-02-18",
customer_id: "cust_123",
order: [
{ product: "paper", qty: 1, cost: 3.49 },
{ product: "pen", qty: 5, cost: 0.99 }
]}Now to know where the order should be shipped, we always need to make a join with the customers table to get the address. Using the extended reference pattern, we copy the necessary information (but nothing more) into the order itself:
In the customers collection:
{ _id: "cust_123",
name: "Katrina Pope",
address: "123 Main Str",
city: "Somewhere",
country: "Someplace",
dateofbirth: "1992-11-03",
social_networks: [
{ twitter: "@me123" }]
}In the orders collection, we now also have the shipping_address key which is a copy of information from the customers table:
{ _id: "order_1827",
date: "2019-02-18",
customer_id: "cust_123",
shipping_address: {
name: "Katrina Pope",
address: "123 Main Str",
city: "Somewhere",
country: "Someplace"
},
order: [
{ product: "paper", qty: 1, cost: 3.49 },
{ product: "pen", qty: 5, cost: 0.99 }
]}4.4.5. Polymorphic pattern
As we’ve seen before, we can create heterogeneous collections where different types of things or concepts are stored in the same collection. But even if each document is of the same type of thing, we might still need a different scheme for different documents. So this is true for documents that are similar but not identical. An example for athletes: each has a name, date of birth, etc, but only tennis players have the key grand_slams_won.
{ name: "Serena Williams",
date_of_birth: "1981-09-26",
country: "US",
nr_grand_slams_won: 23,
highest_atp_ranking: 1 },
{ name: "Kim Clijsters",
date_of_birth: "1983-06-08",
country: "Belgium",
nr_grand_slams_won: 4,
highest_atp_ranking: 1 },
{ name: "Alberto Contador",
date_of_birth: "1982-12-06",
country: "Spain",
nr_tourdefrance_won: 2,
teams: ["Discovery Channel","Astana","Saxo Bank"] },
{ name: "Bernard Hinault",
date_of_birth: "1954-11-14",
country: "France",
nr_tourdefrance_won: 5,
teams: ["Gitane","Renault","La Vie Claire"] },
...4.4.6. Inverse referencing pattern
This is what we saw in the data modelling section for 1-to-immense relationships. Instead of e.g. storing log messages in a server document, store the server in the log messages:
servers collection:
{ id: "server_17",
location: "server room 2" }logs collections:
{ date: "Oct 14 07:50:29", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:35", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:37", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:42", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
{ date: "Oct 14 07:50:39", host: "server_17",
message: "Failed to bootstrap path /System/Library, error = 2: No such file or directory" },
{ date: "Oct 14 07:50:43", host: "server_17",
message: "com.apple.xpc.launchd[1] <Notice>: Service exited due to SIGKILL" },
...4.5. Difference with key/value stores
In a way, document stores are similar to key/value stores. You could think of the automatically generated key in the document store to resemble the key in the key/value store, and the rest of the document being the value. However, there is a major difference: in key/value stores, documents can only be retrieved using their key and the documents are not searchable themselves. In contrast, the key in document stores is almost never used explicitely of even seen.
4.6. Document database implementations
A quick look at the Wikipedia page for "Document-oriented database" quickly shows us that there is a long list (>30) implementations. Each of these has their own strengths and use cases. They include AllegroGraph, ArangoDB, CouchDB, MongoDB, OrientDB, RethinkDB and so on.
![]()
![]()
![]()
![]()
![]()
![]()
Probably the best known document store is mongodb (http://mongodb.com). This database system is single-model in that it does not handle key/values and graphs; it’s only meant for storing documents. Further in this tutorial we will however use ArangoDB because we can use it for different types of data (including graphs and key/values).